B2BaCEO: July 2023 Newsletter
I weigh in on the contest between Databricks and Snowflake, as each vies to own the end-to-end enterprise AI workflow. In short: It’s data all the way down.
07.14.2023 | By: Ashu Garg

Databricks vs. Snowflake: The Battle to Power Enterprise AI
The gloves are off between Databricks and Snowflake, two reigning giants of enterprise data infrastructure. In this fight for mind and market share, generative AI is at the center. Each is staking its claim as the preeminent platform to propel businesses into the AI-first future. As tech history attests, rivalries accelerate innovation, and we could be witnessing one that matches the ongoing contest between Google and Microsoft. As enterprises scramble to derive value from their data, the leading face-off of this decade may be Databricks vs. Snowflake.
Evidence of this intensifying battle was on stark display in late June, when both players held their annual conferences on the exact same dates, in what seemed to be more than a mere scheduling coincidence. Databricks staged its “Data + AI” summit in San Francisco, while Snowflake held court in Las Vegas, forcing enterprise customers to choose. The hot topic at both events was—you guessed it!—generative AI. The top-line message? For an enterprise to successfully implement generative AI, it must begin with a sound data strategy.
As the AI ecosystem matures, it’s become increasingly clear that the performance of generative models turns on the quality of the data that feeds them. While the costs to train, fine-tune, and run custom models plummet, the value of a company’s proprietary data is fast ascending. In the face of these paired trends, both Databricks and Snowflake are positioning themselves as full-service platforms that can help businesses harness the potential of their data and IP. Their struggle for dominance promises to decisively shape the future of modern enterprise data infrastructure, with billions of dollars in potential revenue at stake.
In one corner sits Snowflake. The brainchild of ex-Oracle database architects, Snowflake began its journey as a cloud-native data warehouse specializing in structured data storage. Its SQL-based, closed platform primarily serves data analysts and caters to BI workloads and dashboard creation. Snowflake’s chairman and CEO, Frank Slootman (a two-time guest on my podcast) has cultivated a high-intensity, sales-oriented culture fueled by strategic partnerships and marketing. Armed with a keen understanding of enterprise needs, Snowflake has built a formidable GTM machine and boasts an enviable enterprise sales record.
In the other corner lies Databricks, a product of the academic and open-source communities. Databricks was born as a managed, enterprise-grade version of Apache Spark, an open-source, distributed computing framework that its co-founders conceived as researchers at UC Berkeley’s AMPLab. Designed using open-source systems, its platform caters to ML and data science use cases. Tailor-made for big data and intensive computing, it can handle large volumes of unprocessed data in any format—including the unstructured data (images, videos, audio files, and raw text) critical for training generative AI models. The company’s culture is geared toward product development and engineering, with a clear emphasis on technological innovation.
While these two powerhouses entered the fray at differing ends of the data value chain—Snowflake focusing on storage and Databricks on processing—recent years have seen their offerings converge toward a single vision: to become a comprehensive “cloud data platform” for enterprises. Databricks has pivoted to the “data lakehouse”: a portmanteau of “data lake” and “data warehouse” that combines the benefits of both into a single platform. At the same time, Snowflake has pushed into advanced AI workloads by adding several data-lake-esque features, including support for unstructured data.
Six Months of Rapid Progress
Since generative AI took off at the end of last year, Databricks and Snowflake have mounted a blitz of acquisitions, partnerships, and product releases. Each is wagering that it can edge out the other and become the go-to platform to help businesses evolve from data-driven to fully AI-enabled.
To kick off its summit, Databricks celebrated its $1.3 billion acquisition of MosaicML: an eyebrow-raising sum, even for a well-capitalized company. This deal equips Databricks’ customers with the tools needed to build, train, and own custom generative AI models that are powered by their proprietary data. Just two months earlier, Databricks introduced version 2.0 of Dolly, their commercially licensed, open-source LLM that seeks to perform on par with ChatGPT. To further strengthen its position, Databricks also scooped up Okera, an AI governance tool. In doing so, it made inroads into the realm of security and compliance, which Snowflake has historically ruled.
Not to be outmaneuvered, Snowflake announced its strategic alliance with Nvidia on the same day that the Databricks-MosaicML deal went public. This partnership allows Snowflake’s customers to create bespoke generative AI applications using Nvidia’s NeMo framework and run them on Nvidia GPUs, all within the confines of Snowflake’s Data Cloud. This strategic move follows Snowflake’s purchase in May of the search startup Neeva, which it will use to integrate natural-language search and querying capabilities into its product suite.
Alongside these impressive acquisitions, both contenders let loose a barrage of new, developer-focused offerings at their respective summits. Databricks rolled out Lakehouse AI: a product that spans the full AI lifecycle by convening data, models, FMOps, monitoring, and governance in a unified platform. Vector Search provides access to a curated collection of open-source models, including Mosaic’s MPT-7B, Hugging Face’s Falcon-7B, and Stable Diffusion. Version 2.5 of MLflow introduces AI Gateway, which (among other tasks) manages credentials for SaaS LLM services and model APIs. Prompt Tools, a no-code interface, allows users to track and compare the performance of prompts across various models. In addition, Databricks’ Model Serving has been boosted with LLM optimizations, while its monitoring tools have been similarly augmented.
Snowflake countered with Snowpark Container Services, a Kubernetes-based platform that lets enterprises create, develop, and deploy generative AI applications within its security enclave. This means that businesses can use their data to build AI/ML models and applications without the need to send this data beyond Snowflake’s bulletproof perimeter. The containers support code in nearly every programming language: a leap beyond the company’s long-standing focus on SQL. When paired with the Nvidia partnership, this launch airs Snowflake’s ambitions loud and clear: it aims to be the top choice for businesses eager to tap into the power of generative AI.
A Duel between Two Philosophies
At the heart of the Databricks-Snowflake contest lies a classic dichotomy in software: open vs. closed. Snowflake, with its proprietary storage and compute platform, is a walled garden, built and maintained solely by its own engineers. By contrast, Databricks stands on open-source foundations, which grant its customers flexibility and freedom from platform lock-in. While Databricks allows for greater customization and a wider range of integrations, it also requires the backing of a more technically proficient in-house data team. This is opposed to Snowflake’s “just works” promise.
Is the openness of Databricks superior to Snowflake’s closed approach, or vice versa? The answer is nuanced: it depends! Industry veterans may recall the bold declaration of Cloudera’s cofounder, Mike Olson, in 2013 that “the age of closed-source enterprise infrastructure is over.” Jump forward a decade, and Olson’s words largely hold true—with Snowflake being a notable exception. Operational simplicity and ease of implementation may favor Snowflake, yet Databricks’ commitment to open source means that it stands to gain no matter how the AI landscape evolves. This could prove a decisive advantage at a moment where the only constant is change.
Perhaps open vs. closed is the wrong question, however. The crux of the matter may be: Is enterprise demand for generative AI strong enough to justify Snowflake’s and Databricks’ sizable investments? Both are banking that businesses will want to not only integrate generative AI models into their products and workflows, but also train these models on their proprietary data and own the end results. Databricks’ CEO and cofounder, Ali Ghodsi (a three-time guest on my podcast), recently compared the rise of generative AI on C-suite agendas to the ascendance of big data in the early 2010s. From Ghodsi’s bird’s-eye view, generative AI looks more and more like a font for serious, long-term enterprise investments. This, he contends, is a far cry from fluff for corporate earnings calls.
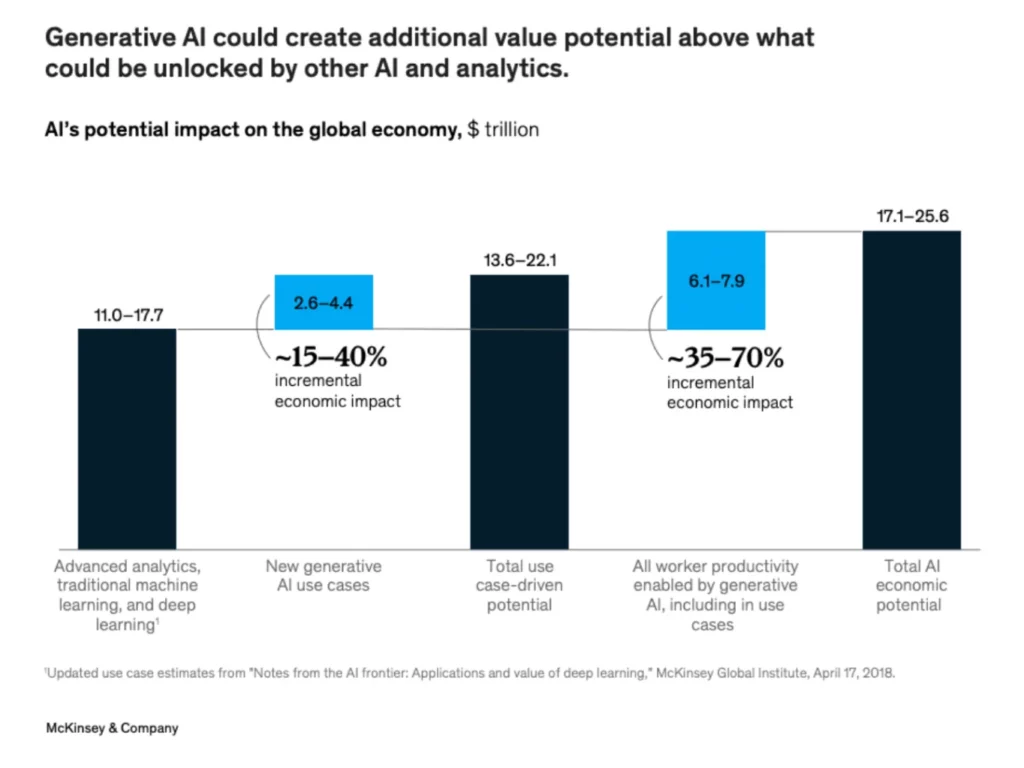
Leading analysts echo Ghodsi’s claim. McKinsey forecasts that generative AI could drive between $2.6 and $4.4 trillion in annual economic gains across industries. This adds to the estimated $11 to $17.7 trillion unlocked by advanced analytics and traditional ML. Bloomberg predicts that generative AI’s footprint will grow from less than 1% of total IT spending to 12% by 2032, with generative AI infrastructure as a service expected to yield $247 billion in incremental revenue by 2032. This is stellar news for both Databricks and Snowflake, and ample reason for both to go all in on this fast-progressing technology.
In the end, business bona fides like GTM strategy and execution may determine which player savors a larger slice of the enterprise AI pie. Currently, many companies use both solutions: according to data from ETR, roughly 40% of Snowflake’s clients also hire Databricks, while about 46% of Databricks accounts run Snowflake. As generative AI models (and their accompanying demands on data) hurtle forward, one winner from this rivalry is clear: the enterprise customer. As Databricks and Snowflake compete to own the end-to-end enterprise AI workflow, their continued moves and countermoves will spur innovation that enables more businesses to leverage generative AI—a win for the entire enterprise ecosystem. And so, I say: “Let the battle rage!”
Portco Spotlight: Watchful
If there’s one takeaway from this month’s editorial, it’s that domain-specific, proprietary data is quickly emerging as the primary accelerant of AI performance. Out-of-the-box LLMs are great for general tasks, but the most impactful AI applications are trained on specialized inputs. These high-value uses of AI center on augmenting subject matter experts, yet these experts are too expensive and pressed for time to manually label the data needed to develop custom models.
Enter Watchful, a suite of tools that streamlines the process of augmenting ML models with domain-specific knowledge. Watchful’s automated labeling solution allows companies to create high-quality training sets from unstructured data in a way that is scalable, observable, and explainable. With Watchful, companies can rapidly label large data sets, ensure accuracy and consistency in labeling, and search their data for both inherent and semantic information. Watchful powers use cases across multiple industries, from finance (fraud detection, AML, contract intelligence) to e-commerce (product cataloging, fraud detection, recommendation systems). Get started here!
Published on 01.31.2023
Written by Foundation Capital


