


Late last year, we published our framework for the enterprise AI stack and gestured toward the potential of foundation models to advance innovation at each of its layers, from AI-optimized hardware, compute, and cloud on up. Yesterday’s release of GPT-4, with its ability to process both text and image inputs, promises to accelerate this paradigm shift in AI, which dramatically reduces the time, technical knowledge, and cost needed to spin up AI-enhanced products.
At Foundation, we believe that the generative powers of GPT-4 and its fellow foundation models will prompt a reimagination of nearly every category of software application. (Google’s announcement of generative AI’s integration across its Workspace suite is a case in point.) Building atop foundation models, however, brings with it a unique workflow: one that creates follow-on opportunities for infrastructure-minded entrepreneurs. To borrow a timeworn Silicon Valley analogy: if applications fueled by generative AI represent the next “gold rush,” prospectors need tools—pans, picks, and shovels—that are purpose-made for the task.
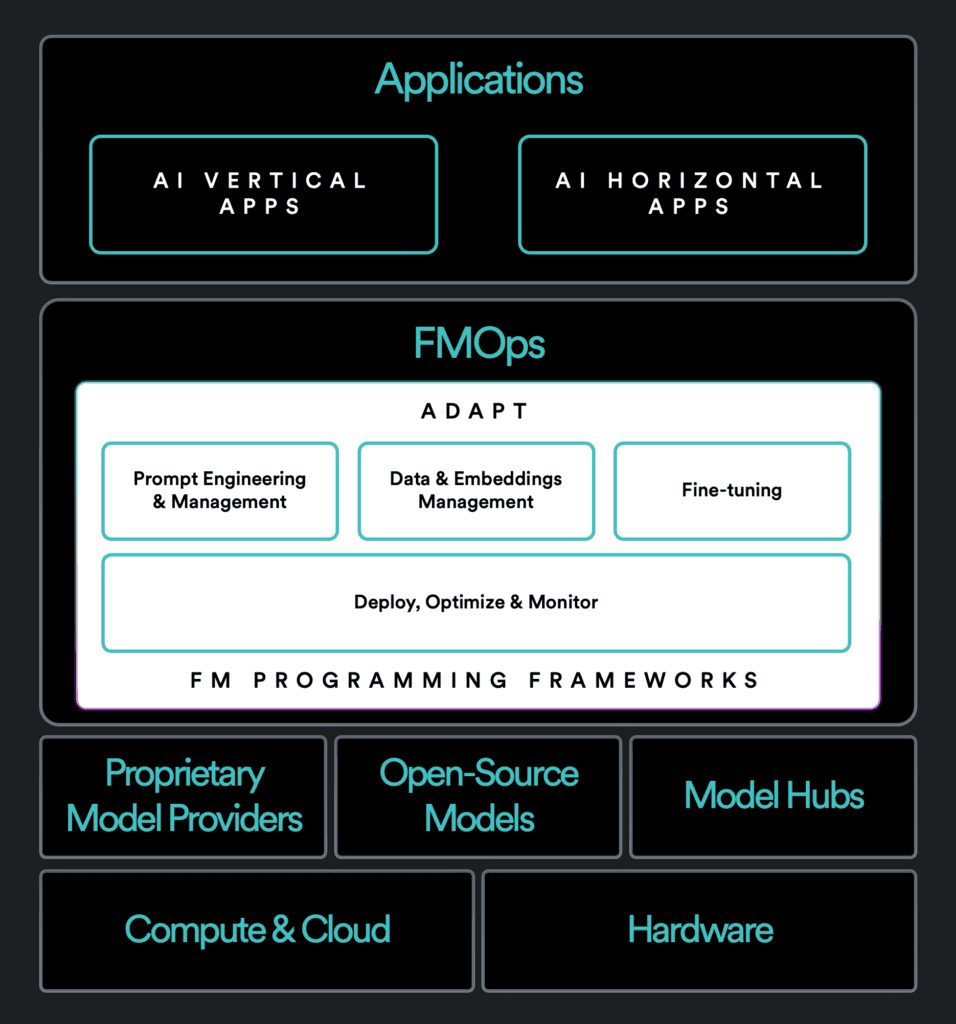
In this post, we inventory the rapidly evolving space of generative AI middleware: what we’re calling Foundation Model Ops, or FMOps for short. These tools, which enable builders to quickly move from foundation models to full-fledged AI applications, fall into three categories:
Adapt: These tools allow users to customize and extend the capabilities of foundation models. We devote the bulk of this post to this category, as it’s here that building with foundation models most diverges from traditional ML workflows—and where the potential to create differentiated generative AI apps lies. Approaches to adapting foundation models fall on a spectrum from light touch to heavy lift, which we simplify as follows:
Prompt Engineering: Tools for designing, adjusting, and optimizing prompts, from templates and marketplaces to management and chaining;
Data & Embeddings Management: Retrieval-based solutions for boosting model performance that make use of embeddings, vector databases, and semantic search;
Fine-tuning: Tools for retraining generalist models on targeted data sets.
Deploy, Optimize & Monitor: These bundled solutions smooth the process of moving foundation models into production and iteratively testing, improving, and observing their performance.
Foundation Model Programming Frameworks: These frameworks orchestrate multiple parts of the foundation-model-to-generative-AI-app workflow. Each helps its users transform foundation models from off-the-shelf commodities into enriched assets powered by proprietary data, third-party APIs, agents, and more.
In the map below, we group startups based on their initial use cases, with some startups spanning more than one category. Given the breakneck pace of progress in this space, this map is by no means complete and is intended to evolve and grow. (Reach out to Jaya Gupta, jgupta@foundationcap.com, to request changes or make suggestions!)

Let’s explore each category and identify places where new startups can plug in.
1. Adapt
Unlocking foundation models’ full potential requires additional tinkering: a process known across academic and industry circles as adaptation. At present, adaptation takes two main forms: in-context learning, or prompting, and fine-tuning. Each approach carries its own set of tradeoffs. Choosing the right one (or combination of the two!) requires builders to consider factors such as budget for compute and storage, the amount and structure of task-specific data available, and the extent of access to the model’s underlying parameters.
Prompt Engineering
While based on standard AI architectures (deep neural networks) and techniques (transfer learning), the sheer scale of foundation models has given rise to emergent abilities. Foremost among them is generation: the ability to create media, whether text, images, video, or audio. Another is in-context learning: the ability to adapt in real time via natural language instructions. These instructions, or prompts, allow users to interface directly with the model and prototype custom functionality without the hurdles of learning a machine-readable language and modifying the model’s parameters. Together with these models’ availability via APIs and open source, this new interaction paradigm radically simplifies the workflow for building an AI product.
Prompt engineering—the process of designing, adjusting, and optimizing prompts to make a foundation model more performant for a specific use case—has surfaced as a net-new category: one that existing MLOps solutions do not support. Below, we detail the core components of the burgeoning prompt engineering ecosystem:
Prompt Templates & Marketplaces:
Effective prompts contain both instructions (commands like “Write,” “Classify,” “Summarize,” “Translate,” “Order,” etc.) and context: examples and additional data that guide the model through a technique known as few-shot learning.
Common types of context include labeled input-output pairs that demonstrate the desired task, real-time data retrieved from a search API, and passages of unstructured data (PDFs, PowerPoints, chat logs, etc.) that are stored and indexed in a vector database (more on this in “Data & Embeddings Management”).
Startups like Promptable and GradientJ offer ready-made templates with placeholders for input variables that automatically suggest starting points and improvements. Others, like PromptBase and FlowGPT, are marketplaces where users can share, discover, buy, and sell prompts for a wide range of use cases.
Prompt Management:
Because prompt design is an iterative, experimental process, builders need management tools that help them organize, track, and collaborate on prompts, along with optimization tools that enable them to A/B test iterations, feed them to multiple foundation models, and measure their performance against industry-standard ML benchmarks (more on this in “Deploy, Optimize & Monitor”). HoneyHive and PromptLayer are two examples of startups in this space.
Prompt Chaining:
Once a prompt is designed, its components can be iteratively adjusted until the model achieves an optimal level of performance. For more sophisticated tasks, multiple prompts can be “chained” together. This entails breaking the overarching task into a series of smaller subtasks, mapping each subtask to a single step for the model to complete, and using the output from one step as an input to the next.
By allowing users to connect multiple calls to a foundation model API in a sequence, chains can power complex workflows that include searching the internet, interacting with third-party tools, querying external databases, incorporating agents, and more. LangChain (covered below in “Foundation Model Programming Frameworks”) offers a standard interface for composing chains that integrates with a range of other tools, along with prebuilt chains for common applications.
Data & Embeddings Management
When authoring a successful prompt, context is key. Think of it as a way to add memory to a foundation model: a feature that the current generation of models lack. In the case of language-based models, context helps avert a key failing: their propensity to “hallucinate,” or fabricate answers that appear plausible but are in fact incorrect.
As discussed above, context can be inserted directly into the prompt. Yet prompt lengths, while growing at an impressive clip (GPT-4, for example, can accommodate 32,000 tokens), can cause this approach to stall. Users may want to insert a full repository of code, the entirety of a website, or a large folder of documents—all of which surpass existing token limits.
One workaround is to connect the model to an external knowledge base. This approach—known as retrieval augmented generation (RAG) and retrieval-enhanced transformer (RETRO), among other names—has been a focus of NLP and deep learning research in recent years1. Adding this secondary store of information involves linking the model to an external database, along with a retriever that can interact with the database, query its contents, and pass data back to the model. Today, the state of the art is to make use of a vector database, such as Pinecone or Weaviate, which stores data as embeddings. These embeddings power semantic search, which enables relevant information to be identified and delivered to the model at the time of prompting. Other approaches to retrieval include calling a search API (as in the case of WebGPT) or querying a structured database.
Given the promise of this space, new solutions for storing, indexing, and feeding external knowledge to foundation models are quickly emerging. One example is LlamaIndex: an LLM programming framework whose centralized interface allows users to load external sources including local file directories, Notion, Google Docs, Slack, and Discord; construct an index and perform queries over it; and share pertinent information with the model.
Fine-tuning
The second, heavier-lift approach to adaptation is fine-tuning, which involves altering the foundation model’s underlying parameters by retraining it on a more targeted data set. An established technique that dates back to the ImageNet Challenge of the 2010s, fine-tuning can achieve token and cost savings from shorter prompts, eliminate the need for orchestration with secondary stores of knowledge, and reduce latency.
Doing it alone, however, requires technical expertise, lots of storage and compute, and a commitment to regularly retraining the model as new data is produced. Fine-tuning can also introduce problems such as overfitting (the model becomes too specialized on the training data and fails to generalize well to new data) and catastrophic forgetting (the retrained model loses its ability to recall previously learned information).
OpenAI lets users fine-tune its models for a fixed cost per token used in training and inference. Other startups, like Humanloop and Vellum, bundle fine-tuning as part of a broader LLM development platform, with tools for data sample selection, data distribution mapping, and post-fine-tuning evaluation.
While OpenAI and other foundation model providers, like Google, are launching capabilities in this space, we believe that application builders will derive the most value when their “Ops” are not tied to a single model provider. In addition to creating cross-provider interfaces, new entrants can add value by supporting other modalities of data (image, video, audio, multimodal, and so on) and helping users weigh the tradeoffs among different adaptation approaches—for example, by offering transparency into their cost savings and performance gains.
2. Deploy, Optimize & Monitor
Once a foundation model is adapted, the next step is to deploy it and continuously optimize and monitor its performance. OpenAI, Google, and MLOps incumbents, like Arize, are making forays into this space. Startups like HoneyHive and Vellum are also tackling multiple stages of this workflow for generative AI applications, with features that allow users to:
Easily switch between different models and model providers via a unified interface
Organize and version prompts, models, and proprietary data
Track and visualize prompting and fine-tuning experiments in real time
Determine the optimal bundle of prompts, parameters, models, and model providers for a given use case (for example, through A/B testing frameworks)
Measure the performance of models in production and evaluate them against industry-standard benchmarks
Passively collect training data by capturing model inputs, outputs, and human feedback
Automatically retrain models as new training data is collected
While most of the startups in our market map concentrate on language models, offering support for images, video, and audio will be increasingly critical as multimodal models become the state of the art.
3. Foundation Model Programming Frameworks
These frameworks span the middleware stack and support multiple stages of the workflow for building a generative AI app. For example, LangChain, discussed above in “prompt chaining,” is a Python-based interface that orchestrates the many steps involved in engineering an effective prompt. Its features run from prompt templates to integrations with document loaders, embedding models, vector databases, third-party APIs, and agents. Other frameworks with strong early momentum include Dust and Klu, which support chaining, model swapping, versioning, caching, semantic search, deployment, and automated optimization, among other functions. Further opportunities exist for visual programming solutions that allow non-experts to combine prompts into end-to-end workflows.
Call for Startups
If you’re building atop foundation models, or you’re excited to make the picks and shovels to help others do so, we’d love to hear from you! Get in touch at agarg@foundationcap.com and jgupta@foundation.com. We’ll be hosting an AI hackathon at our SF office on Wednesday, March 22 starting at 4 pm. Click here to apply!
Special thanks to all who contributed to this piece, including Shyamal Anadkat, Hunter Brooks, Aparna Dhinakaran, Courtney Fiske, Jeremy Liu, Andrew Han, Mohak Sharma, and Stephen Walker.
Benefits of this approach include containing model size by reducing the number of parameters needed to ingest and store ever-expanding amounts of knowledge; improving trust and reliability by linking knowledge to known sources; raising visibility into what the model does and does not know; and permitting models to be updated, manipulated, and adapted without the need for retraining, among others.