Year One of Generative AI: Six Key Trends
12.11.2023 | By: Jaya Gupta, Ashu Garg

Just over one year has passed since the release of ChatGPT. In the intervening twelve-odd months, it’s become abundantly clear that generative AI represents a fundamental platform shift. Leaders in the field now regard LLMs as the backbone of a new operating system capable of coordinating a variety of tools and resources to independently solve complex problems.
In this post, drawing on countless founder meetings and pitch decks, we distill our first-hand learnings into six trends that have defined the generative AI space throughout 2023 and that are set to shape its trajectory in 2024. We’ve split these trends evenly between the infrastructure that underpins generative AI models and the application layer where their potential is harnessed by everyday users. Throughout, we use the terms LLMs, generative AI, and foundation models interchangeably. This choice reflects our belief that LLMs will increasingly become multimodal, as already seen in GPT-4 and Google’s Gemini.
Before we turn to these trends, let’s quickly recap the developments of the past year.
Looking Back at 2023
In 2023, generative AI has compressed the full arc of a technology hype cycle into one year.
Phase one (November to February) was marked by alternating waves of euphoria and apprehension. ChatGPT became the fastest-ever application to reach 100 million monthly active users: a feat that it achieved organically in just six weeks. San Francisco’s startup scene roared back, with Cerebral Valley as its center. Early adopters of LLM APIs, like our portfolio company Jasper, reaped the benefits of being first movers. However, this period also saw massive overconfidence in private markets, with $100 million pre-product seed rounds and indiscriminate funding of teams with DeepMind pedigrees.
During phase two (March to June), the challenges of moving from concept to production became increasingly clear. The hype continued, with daily announcements of new open-source LLMs and a flurry of startups debuting demos on Twitter. Auto-GPT, an open-source AI agent, became the fastest-growing GitHub repository in history. As focus in AI shifted from research to product and UX, a new role—the AI engineer—gathered momentum through content and hackathons. Yet, when startups tried to go beyond demos to production-ready products, they encountered a range of hurdles, including issues with hallucinations, usage drift, and context parsing. In parallel, enterprises struggled with lengthy planning cycles and concerns over the security and privacy of generative AI models. While public earnings calls were laced with AI buzzwords, tangible improvements in margins or products were less evident.
Phase three (June to present), while still seeing some early beneficiaries, has largely been a period of recalibration and reflection. Our portfolio company, Cerebras, a longtime leader in AI hardware and training, launched a partnership with G42 to build the world’s largest AI supercomputer. NVIDIA’s stock price surged, buoyed by record demand for GPUs. At the same time, generative AI developer frameworks like LangChain that found early, explosive growth faced backlash for failing to achieve the right levels of abstraction. OpenAI dramatically fell apart, only to quickly come back together.
Against this backdrop, we saw six key trends emerge.
Six Trends that Defined Generative AI in 2023
INFRASTRUCTURE
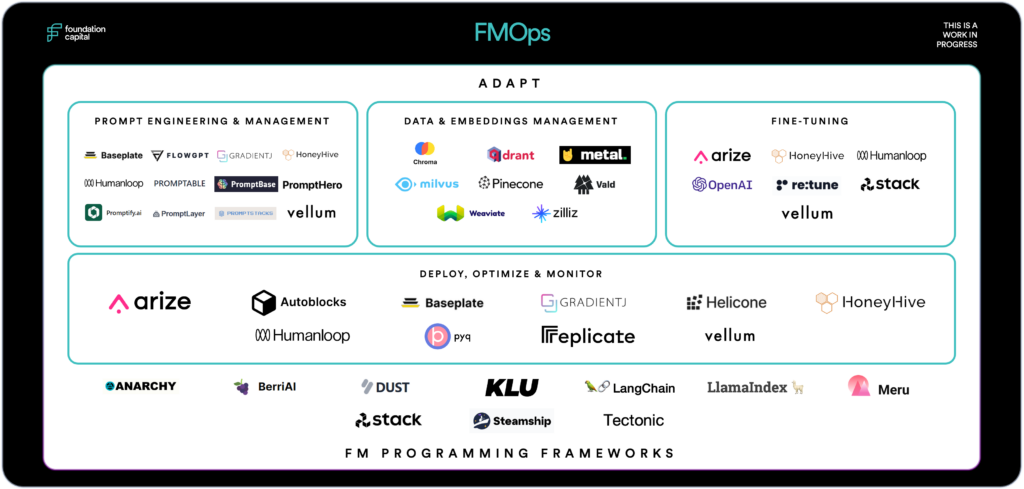
Unlike the first generation of CNN-, RNN-, and GAN-based AI startups, the generative AI wave has seen a cohort of AI infrastructure providers gain tremendous traction. Together, they comprise a “generative AI stack”: a suite of tools around data pipelines, model deployment and inference, observability and monitoring, and security needed to put LLMs into production. This stack is highly fluid, as the ideal architecture for building generative AI apps is rapidly evolving.
With this as a caveat, let’s explore three themes that we’re watching in the generative AI infrastructure space.

Retrieval-augmented generation, or RAG, pairs LLMs with a retrieval mechanism that relays information from an external knowledge store during the generation process. By anchoring LLMs in curated, reliable sources of information, RAG ensures that their responses are both accurate and contextually relevant. In doing so, it reduces risks like hallucinations and unintended data leaks. It allows developers to design applications that adapt to the ever-changing state of the world, without the need for constant (and costly!) model retraining. RAG systems can also link to sources, making their outputs more transparent and trustworthy.
Anecdotally, we’re finding that around 80% of all LLM app builders are using RAG in some capacity. As RAG becomes widespread, a set of best practices around system design is emerging. The process begins with identifying sources of relevant data, which may include CRM, ERP, and CMS systems, along with internal communication tools, cloud storage services, and other SaaS applications. This data is then extracted, transformed, and fed either directly into the model’s context window or an external database for future retrieval.
Vector databases are particularly well-suited for RAG architectures, as their design aligns with the ways that LLMs represent, understand, and process information. Storing information in a vector database involves breaking it down into smaller units, or “chunks,” and passing them through an embedding model, which distills their meaning in numerical form. This transformation allows information to be indexed and retrieved based on its semantic similarity to a user’s query, rather than simple keyword matching.
An ongoing debate is whether recent generative-AI focused products like Chroma, Pinecone, and Weaviate will win out over existing data storage solutions, like Databricks, Elastic, MongoDB, and Postgres. Despite the early success of dedicated vector databases (especially among startups), it’s our belief that incumbents will eventually dominate by adding vector search to their offerings.
Open challenges with RAG include effective chunking methods for documents, selecting the right embedding model based on use case, optimizing search over vectors, and evaluating overall system performance. Notable startups in this space include Metal (ML embeddings as a service), Unstructured.io (ETL for LLMs), and our own portfolio company, Arize (evaluations for RAG).
To double-click on RAG evals, we’ve heard from many teams that they’re simply eyeballing outputs. Arize’s open-source observability library, Phoenix, allows users to easily detect gaps in their knowledge base and identify instances where irrelevant content is retrieved. It addresses critical questions such as: Does the retrieved data include information that addresses the user’s query? What is the optimal size and number of chunks to retrieve? And, most importantly, is the overall system’s response accurate?

The term “AI agent” is at once expansive and nebulous, summoning everything from an innocuous chatbot to a rogue, humanity-ending robot. Broadly construed, an AI agent is a system that can perceive its environment and autonomously execute tasks through reasoning. Current techniques for building agents vary widely, from simple chains of LLM responses to more complex architectures that convert goals into actionable plans, interact with APIs, and harness a variety of tools. BabyAGI, Auto-GPT, and AgentGPT are notable examples.
This year, we saw an explosion of pitches related to this concept, including frameworks for creating and managing agents, strategies for optimizing agent chains, tools for evaluating agent performance, and marketplaces for buying and selling agent services. Across these pitches, a common focus was on improving the interface between agents and humans. One interesting idea is an interface that allows users to directly influence an LLM’s reasoning process through intuitive actions like dragging, dropping, and editing.
To achieve a complex task, an AI agent must break it down in a series of smaller, sequential steps. Task breakdown and synthesis are thus important areas of focus in agent development. An interesting contribution is CAMEL (Communicative Agents for “Mind” Exploration of Large-Scale Language Models), introduced in an arXiv paper submitted this March. In this approach, three AI agents collaborate: one to provide instructions, a second to propose solutions, and a third to specify tasks. We’re closely following this framework and others like it, as we believe that future breakthroughs in the agent space are likely to result from models interacting iteratively in simulated settings.
For all their promise, AI agents remain in a nascent stage of development. At present, they excel in limited, tightly defined scenarios but struggle with repetitive looping, task deviation, limited situational awareness, and latency issues. Because AI agents are effectively reasoning engines, improving their performance will require models that are better optimized for reasoning: a concept that is itself highly complex and open to definition by a range of heuristics. Startups like Imbue are tackling this challenge by focusing on training models with code, one of the most explicit forms of reasoning data that exists on the internet.

Last month’s upheaval at OpenAI was a stark reminder of the risks associated with relying on a single model provider. To mitigate these risks and enhance product performance, the best practice is to employ an ensemble of open-source and proprietary LLMs, with a routing architecture that dynamically assigns tasks to the most suitable model. Recent research points to increasing enterprise adoption of a multi-model strategy, with about 60% of businesses making use of routing architectures.
Alongside large-scale foundation models, we’ve also seen a trend toward smaller, bespoke models. Customized with domain-specific data and proprietary knowledge using platforms like Outerbounds (one of our portfolio companies), these smaller models often outperform their larger counterparts on specific tasks and offer additional advantages such as lower costs, faster response times, and greater control over model behavior.
As generative AI continues to progress, software solutions that allow companies to easily switch between models and delegate tasks among them will become increasingly important. Another of our portfolio companies, Anyscale, built atop the open-source distributed computing framework, Ray, offers just such a solution for enterprise AI. (Check out our recent B2BaCEO podcast with Anyscale’s co-founder and CEO, Robert Nishihara, where he discusses this trend.)
APPLICATIONS
In 2023, endless ink was spilled over how startups can build defensible generative AI applications. Incumbents hold impressive advantages, including scale, distribution, brand recognition, and vast engineering resources. When it comes to incorporating generative AI as an “add-on” to existing products, incumbents have the upper hand.
Yet, as generative AI catalyzes fundamental changes in workflows and user behaviors, the competitive calculus changes. In this scenario, startups can create and find wedges in multi-billion dollar markets. For founders, the key lies in creating products that are designed from the ground up around generative AI, rather than making incremental improvements that incumbents can copy-paste. As always, startup success depends on addressing real user needs and targeting underserved markets.
With this in mind, here are three opportunities in the generative AI application layer that we’ve been tracking.

Generative AI allows startups to shift their focus from enhancing individual productivity to creating and selling complete work products. In industries that have been relatively untouched by AI, including accounting, auditing, back-office operations, legal services, patent writing, and recruiting, the potential for innovation is vast. In recruiting, for example, software spend stands at around $2.5 billion against a market size that exceeds $30 billion.
This shift will take time to play out. Yet, as generative AI sets a progressively higher bar for services, it will force service-oriented companies to rethink their value props. In parallel, it will give rise to new software pricing models. Breaking with the per-seat billing of traditional SaaS, these models will reflect the direct outcomes and added value created by AI. This evolution in pricing will also impact the clients who are using these applications. For example, in consulting and legal professions that rely on billable hours, the efficiency gains brought by AI tools could make unit-based pricing obsolete.
With generative AI, startups can also begin to address business challenges on a system-wide scale. Consider, for instance, a generative AI tool for marketing: it could leverage customer data from across a business’s network to autonomously design, test, and launch targeted campaigns. Similarly, a generative AI product could aggregate and analyze data from different points in a supply chain to proactively manage demand fluctuations, navigate disruptions, and optimize logistics. This approach marks a significant expansion in the scope and impact of AI applications, heralding a new era of SaaS where the emphasis is on improving efficiency across entire systems, not just individual workflows.

The prevailing wisdom in AI development holds that the more varied and higher quality the data, the better the resulting AI model. This has led to the hypothesis that AI startups can build defensibility through data flywheels, where increased usage leads to more data, which in turn improves the underlying model, attracting further usage, and so on.
While this concept still holds true, particularly in industries with siloed and difficult-to-obtain data, the belief that data moats alone confer an enduring competitive advantage is beginning to fray. Researchers have found diminishing returns to AI scaling laws, suggesting that amassing ever-greater quantities of data is not a guaranteed path to AI success. What’s more, depending on the domain, hard-won data advantages could be wiped out by the next foundation model release.
As a result, the data strategy for AI-centric companies must be more nuanced than simply “more is better.” At its most basic, it needs to align with the specific objectives of the model under development. For example, while publicly available data can be a useful starting point for foundation model training, it often carries biases and may not be well suited for targeted tasks. Innovative data generation methods, such as the use of simulations (as discussed with the CAMEL framework in theme 2), may prove increasingly important moving forward.
Customer-generated data stands out as a particularly valuable asset, given its high relevance, real-time nature, and how difficult it is to replicate. In our view, the most successful generative AI companies will establish intuitive feedback loops that engage users and integrate their input to continuously refine models. Additional moats may lie in interface design, sticky workflows, and system integrations. Amid these evolving trends, one thing is clear: in the next wave of generative AI apps, foundation models will be just one part of a holistic product.

When paired with generative AI, vertical software becomes exponentially more powerful. By incorporating LLMs, vertical AI solutions can better customize workflows, automate bespoke tasks, and tailor experiences to each organization and user. Two of our portfolio companies—ConverzAI, which is building a voice-powered, generative AI agent for recruiting, and Docket, which allows businesses to virtually clone their top sales engineers—are prime examples. Other vertical AI startups in sectors with large TAMs and relatively low rates of generative AI adoption, including accounting, consulting, construction, financial services, and healthcare, show promise.
To date, vertical software has been limited to industries with large amounts of clean, structured data. The advent of LLMs capable of handling unstructured data, including emails, PDFs, and multimedia content, dramatically expands the reach of vertical AI solutions. Alongside foundation models, the growth of vertical AI is also being driven by the development of smaller, specialized models. As discussed in theme 3, these models—customized with industry-specific data and processes—can often provide better performance at lower cost than adapted foundation models.
Call for Startups
As we look toward 2024, we’re more optimistic than ever about the novel products and experiences that generative AI will enable. If you’re a founder building with generative AI, whether on the infrastructure or application layer, reach out at jgupta@foundationcap.com or agarg@foundationcap.com.
Published on 12.14.2023
Written by Jaya Gupta & Ashu Garg