


Introduction
When it comes to generative AI, the only thing that’s constant is the speed at which this technology is changing. Over the past few months, we’ve spoken in-depth with a diverse range of builders and technologists who are exploring generative AI. From engineers at large-scale enterprises who are integrating this technology into their processes and products, to early-stage founders creating net-new experiences, we’ve gathered a wealth of insights that can be learned only by doing. Focusing on the unique needs of enterprises, we’ve transformed these learnings into a clear, step-by-step framework for leaders who are aiming to introduce LLMs into their organizations. In this post, we’ll walk through each step in detail. Let’s get started!
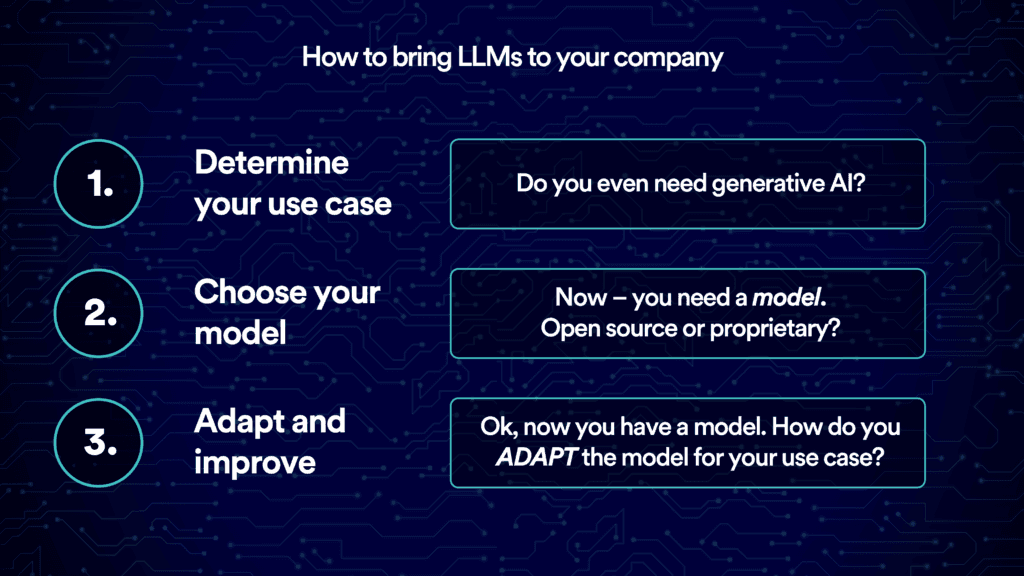
Step 1: Determine your use case
The first step is to figure out where and how it makes the most sense to apply generative AI. Doing so means understanding your business’ needs and how these needs map onto the unique capabilities of generative AI.
Today, we’re seeing LLMs be widely used in both internal operations and customer-facing applications, particularly in scenarios that involve creating and processing text, audio, and images, as well as generating code. A natural place to start is with natural-language-based tasks that keep humans in the loop, from customer service and sales to marketing and product development.
When considering use cases, here’s a helpful question to ask: Are you planning to use generative AI mainly as a tool to enhance your current workflows and products? Or are you hoping to use its capabilities to offer services that would be considerably more difficult (or even impossible) without it? The latter might involve crafting complex interactive experiences, personalizing content at scale, or automating high-level writing or editing tasks. Just as Uber was enabled by the net-new features of smartphones, like GPS, internet connectivity, and touch screens, the former tasks are uniquely enabled by LLMs.
There are also certain areas where enterprises should exercise caution when using LLMs. These include high-stakes situations, where the cost of errors could be significant, along with high-volume decision-making processes, due to their steep inference costs. Generative AI works by predicting the “next best” token, so it can sometimes produce “hallucinations”: statements that sound believable but are actually false. Strong measures around data security and privacy must be established to ensure that sensitive information does not end up in the model outputs in ways that can be identified. In addition, you’ll need to be aware of IP risks, such as the potential for copyright infringement, especially when using third-party models.
Step 2: Choose your model
Once your use case is clear, the next step is to decide the best way to deploy generative AI to achieve it. Let’s break down your options and review the key considerations that should guide your choice.
Option 1
DIY: Build your own model
The most hands-on option is to train your own LLM from scratch. This approach gives you total control over the data used to train the model and the most robust privacy and security guarantees. But, keep in mind, doing so requires a serious amount of data and computing power, together with a deep bench of in-house AI expertise. For example, training OpenAI’s GPT-3 model on the lowest-cost GPU cloud provider is estimated to cost around $4.6 million: a price tag that does not include research and engineering, plus millions more for data collection and evaluation. You'll want to make sure that the added value from using a fully custom model is worth the investment of time, money, and human resources.
Option 2
Off-the-Shelf: Buy a ready-made generative AI application
At the other end of the spectrum, you can opt for a ready-made SaaS tool, like a generative AI-based code-completion product that integrates with your organization’s existing software development stack. This option is convenient and far less resource-intensive than starting from scratch, but it offers little room for customization. For example, the generative AI tool described above may lack knowledge about your organization's specific coding style, schemas, and conventions.
Option 3
Middle Ground: Adapt a pre-trained LLM for your use case
If you’re searching for a middle ground, adapting a pre-trained LLM might be your best choice. In this case, you take an existing LLM as your starting point and supplement it with additional data to fit your specific use case. While training LLMs from scratch is an intensive process, fine-tuning LLMs is significantly faster, cheaper, and requires less data, thus making it a viable option for many enterprises.
If you decide to pursue this route, next up is to decide what type of base LLM to configure: proprietary or open-source. Each has its own pros and cons, and it's crucial to align your choice with your business's needs, available resources, and potential risks.
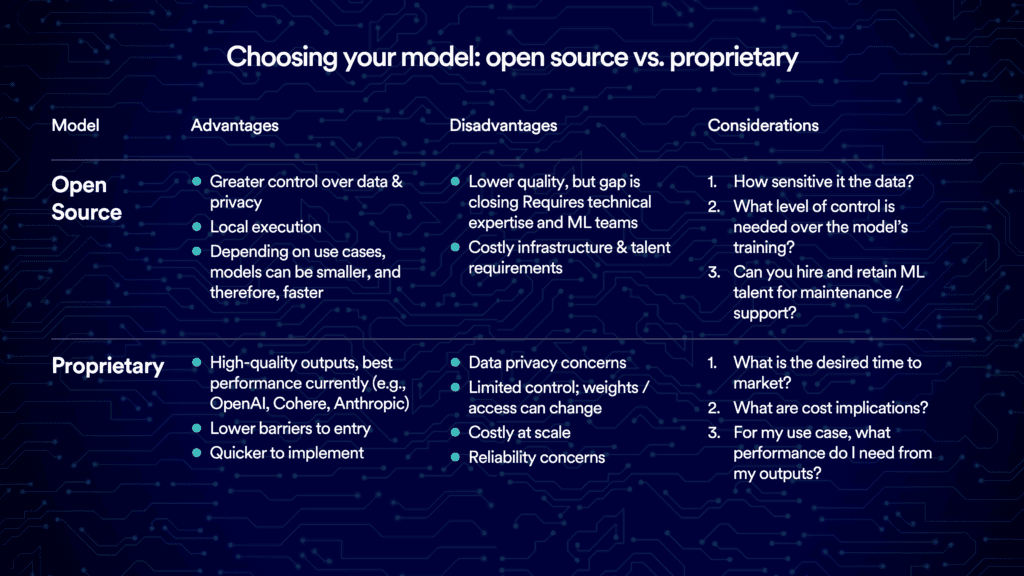
Proprietary models are closed-source, meaning the model's architecture, parameters, and training data aren't publicly available. The developer of the foundation model typically offers access to the model via an API through a licensing agreement.
The primary benefit of proprietary models is their impressive performance across a wide variety of tasks. They’re also easy to use and come with managed infrastructure, which allows you to get up and running quickly. The main costs here may include a user interface build, integration with your company's internal systems, and establishing risk and compliance controls.
On the downside, proprietary models’ consumption-based cost structure means that, for some tasks, they can be about 10x more expensive than their open-source counterparts. For simple, focused tasks, their performance may be more than you need, and smaller open-source models might be more cost efficient. And while proprietary models often come with built-in content moderation capabilities, you need to carefully consider potential compliance and security risks, especially when sending sensitive customer data to a third party. Keep in mind, too, that a third party can change model weights and access or even retire certain models.
Open-source models, on the other hand, offer code that anyone can access and modify. They are quickly catching up to their proprietary counterparts, as the performance of Meta's Llama 2 attests. Llama 2 follows on open-source releases from leading organizations like Databricks, Cerebras, MosaicML, and Stanford, all of which boast impressive capabilities.
The appeal of open-source models lies in their transparency and flexibility. These qualities that prove critical in heavily regulated industries. Depending on your task, you might find smaller open-source models perform just as well as larger proprietary ones. Plus, by training and running open-source models locally, you can maintain full control over data privacy and security.
Independent model hubs, like Hugging Face, are quickly emerging to aggregate open-source models and offer end-to-end MLOps capabilities, including the ability to fine-tune LLMs with proprietary data. These capabilities are also supported by companies like Anyscale and Outerbounds, which are built atop open-source foundations.
In the end, the choice between open-source and proprietary models isn’t binary. You may find value in a hybrid approach that leverages the strengths of both. As the LLM landscape continues to evolve, the key is to stay flexible and make informed decisions that push your business forward.
Step 3: Adapt and improve
If you decide to pursue option 2, you’ll next need to adapt your chosen LLM to your use case. To do so, you’ll need to understand how LLMs work in production today.
How LLMs work in production today
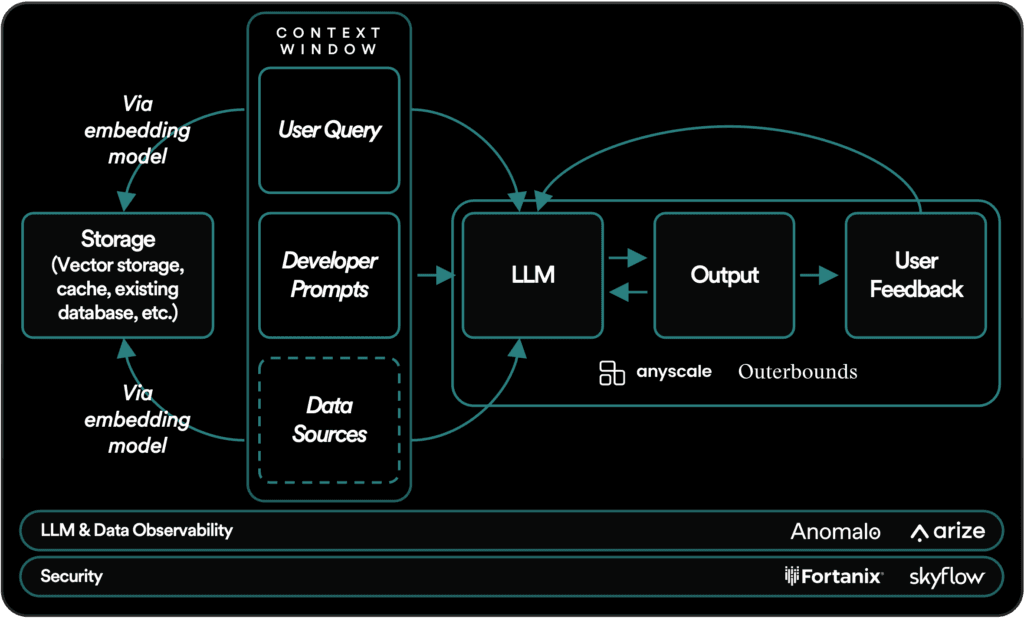
At the heart of an LLM's operation is the “context window.” Think of it as your input area, which is limited by a certain number of words or tokens. It's important to optimize this token count, as more tokens mean more latency and cost.
LLMs interact with user queries through developer or system prompts. These prompts guide the LLM: for example, by directing it to avoid using explicit language or providing illegal information. After receiving the user’s input, the model generates a response. At this step, implementing a feedback mechanism can dramatically improve the model's performance. This could be as simple as a thumbs-up or thumbs-down, or a more complex rating system. Either way, this feedback guides the iterative improvement of your model.
For tasks that require domain-specific or up-to-date knowledge, you’ll need to supplement your LLM with proprietary data. This process of augmenting your model with external “memory” typically involve converting your data into embeddings, which are stored and retrieved when relevant to user queries.
Next up is security. Sensitive data, including PII and financial, health, and employment information, must be handled with extreme care. Companies like Skyflow and Fortanix specialize in data anonymization, redaction, tokenization, encryption, and masking, which can help address some of these security concerns.
Observability—the ability to monitor and understand what’s happening inside the model based on its outputs and other visible signals—is similarly key for enterprise use cases. It allows ML engineers, software developers, and data scientists to ensure that the LLM is behaving as expected, identify and tackle problems when they emerge, and gain insight into ways that the LLM can be iteratively improved. Anomalo offers fully automated data quality and monitoring, while Arize provides a suite of tools for evaluating LLM outputs, pinpointing areas for prompt-engineering improvement, and identifying fine-tuning opportunities.
Three ways to adapt an LLM for your use case
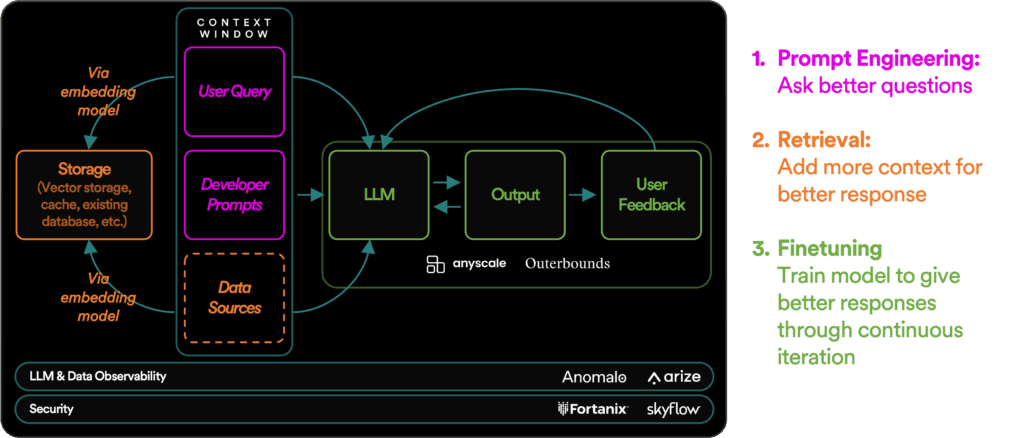
When integrating an LLM into your operations, there are three main strategies that you can use to boost its usefulness and accuracy: prompt engineering, context retrieval, and fine-tuning. Let’s take a closer look at each one.
Method 1: Prompt engineering
Prompt engineering is the process of designing, refining, and optimizing input prompts. This is less a science than an art. It involves carefully crafting user queries, adding clear-cut instructions, and inserting additional data that steers the LLM's responses. This approach reduces ambiguity, saves computational resources, and helps minimize hallucinations.
Method 2: Context retrieval
A more advanced technique is context retrieval. Think of this method as giving your LLM a “memory bank” by connecting it to external data sources. This process begins with a user query that serves as a trigger. The retrieval function then sifts through a database (commonly a vector database) to find relevant content. This content is then retrieved and passed into the LLM’s context window to guide its output.
Implementing context retrieval involves three main steps. First, you need to break down your data into smaller pieces—what is known as "chunking." Chunking is an iterative process and can sometimes lead to imprecise search results or missed opportunities, as important patterns may get lost in the segmentation. Take one of our portfolio companies that uses customer call transcripts as their data source as an example. They had to iterate for two months before realizing that the optimal chunking approach was to segment by the “speaker” name in the call. You'll likely need some in-house technical expertise to determine the best chunking strategy for your needs.
Next, you'll need to pick a search method. Anecdotally, while many builders opt for the similarity search method, combining multiple techniques (like clustering, sequence search, and graph-based methods) can produce better results.
Finally, you'll need to choose a database. Local storage might be sufficient in the early stages, but as you reach very large scale, you'll probably need to either extend your existing databases or explore vector databases. As always, it's important to keep data security and privacy top of mind. Storing customer data with third parties could potentially lead to issues around data retention, data breaches, and data sovereignty.
Method 3: Fine-tuning
Fine-tuning refers to the process of taking a pre-trained model and tailoring it to a specific use case by training it further on a smaller, task-specific dataset. It’s the most resource-heavy adaptation method and involves altering the LLM’s underlying parameters. But unlike training an LLM from scratch, which demands multiple terabytes of data, fine-tuning can be successfully performed with several hundred or thousand examples. Companies like Anyscale and Outerbounds offer end-to-end solutions to support enterprises in creating production-grade, fine-tuned LLMs.
If you're looking to achieve a certain brand style or voice, accomplish a domain-specific task, or augment an LLM's reasoning skills, fine-tuning can yield impressive results. It's less effective with larger, more capable models, where the incremental improvements may not justify the investment. In addition, despite its potential benefits, fine-tuning has its challenges, including the need for in-house technical knowledge and high-quality data. Companies often turn to platforms such as Turing to access a global pool of talent to tackle these hurdles.
Summary
This chart below summarizes the challenges and considerations that enterprises should weigh when deciding which of these three adaptation methods to pursue.

Conclusion
Still at a loss with where to begin? It's important to remember that starting small is better than not starting at all! Don’t be afraid to launch an internal pilot and learn as you go. Rather than experiment in a silo, involve multiple stakeholders, from engineering and data science to design, product, and legal.
Keep in mind that a modern data and tech stack is crucial for any successful foray into generative AI. You'll need pipelines that provide easy access to high-quality, domain-specific data. A scalable data architecture that includes robust guarantees around data governance and security is also indispensable. Lastly, depending on your ambitions, you may need to augment your existing computing infrastructure and tooling stack.
Reach out!
If you’re an enterprise leader exploring LLMs, or a founder working to solve problems discussed in this post, we’d love to hear from you! Drop us a note at agarg@foundationcap.com and jgupta@foundationcap.com.