Where AI is Headed in 2025: A Builder’s Guide
04.26.2024 | By: Ashu Garg

It’s no longer just about training bigger and bigger models. I chart the growing shifts toward inference and compound AI systems and explain what they mean for founders.
Just 18 months ago, ChatGPT ignited an AI revolution that has since accelerated at a blinding rate. From speculation about AGI’s imminent arrival to Sam Altman’s sudden departure and swift return as OpenAI’s CEO, the rise of open-source models that rival their closed counterparts, and Meta’s integration of its AI chatbot across its entire app ecosystem (which reaches 40% of the world’s population), the AI field has seen abundant drama, and even more abundant progress.
In this month’s newsletter, I’m taking a step back to reflect on the monumental strides AI made in 2023 and chart how this ecosystem is likely to evolve in 2024 and 2025, with a particular focus on the enterprise. The field is advancing at such an extraordinary rate that both founders and enterprise leaders need to anticipate where the metaphorical puck is headed and skate toward it. If a model can perform a task 40% of the time now, odds are that it will achieve that same task 80-90% of the time in a year or two. The most astute builders will design solutions for the capabilities that models will soon have, rather than limiting themselves to what’s possible today.
My goal this month is to give founders a guide for doing just that.
2023: A year of training and performance gains
2023 was a landmark year for AI, with advances happening faster and at a more sweeping scale than ever before. 149 new foundation models were released, more than doubling 2022’s count. The relentless pace of progress in training was mirrored by the surge of AI activity on GitHub, where projects related to AI jumped by nearly 60% and engagement with them (measured in terms of stars) tripled year-over-year to more than 12 million.
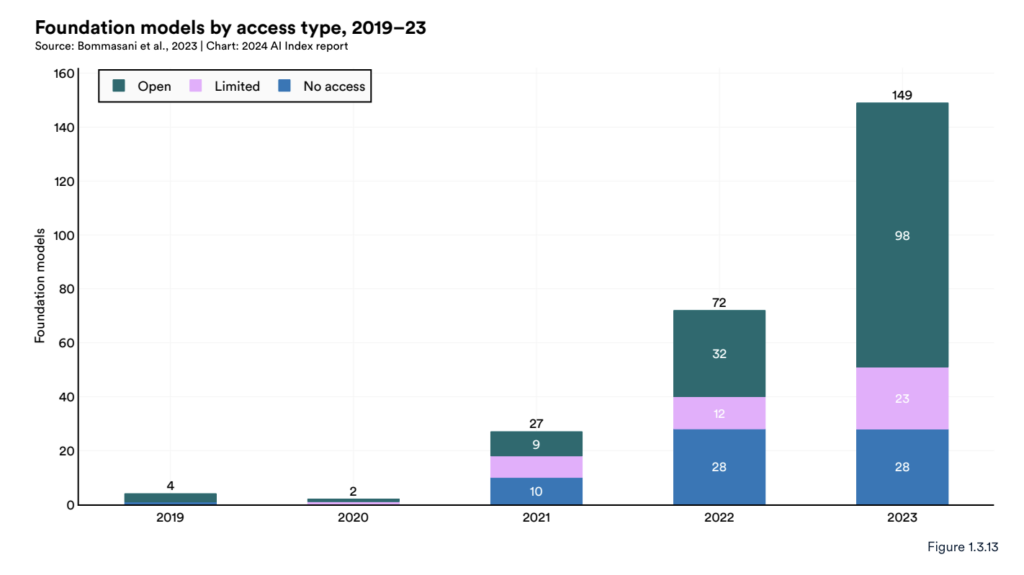
The transformer architecture was the driving force behind this explosion of innovation. As researchers fed these models ever-increasing amounts of data and compute, they continued to improve, confirming the hypothesis that transformer models have “scaling laws” akin to Moore’s Law in semiconductors. Transformer-based models began saturating benchmarks like the gold-standard MMLU, compelling researchers to develop new, more challenging tests to keep pace.
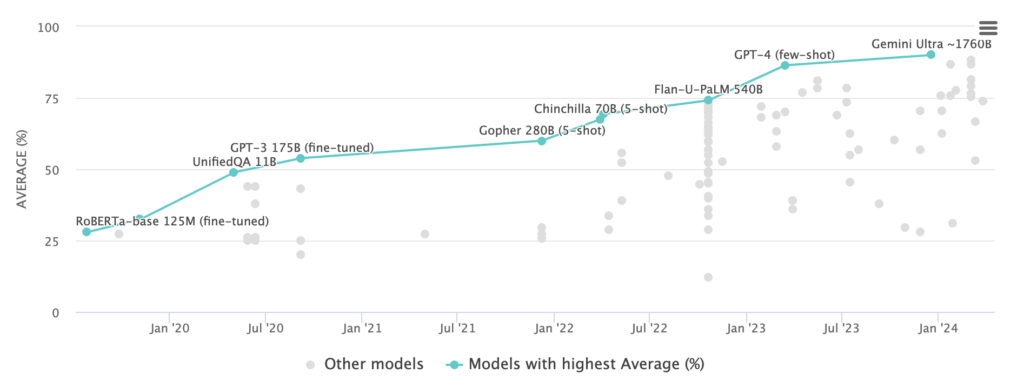
In parallel, multimodal models unlocked new use cases across language, vision, speech, and robotics. Since November 2022, we’ve lept from ChatGPT, which could handle 4,096 tokens of text, to Gemini 1.5, which can process one million tokens across text, images, audio, and video. Gemini’s research team reports increasing capabilities in next-token prediction and recall across up to at least 10 million tokens, hinting at the vast potential that remains untapped in these models.
Together, these developments led to a shift in AI’s competitive landscape. OpenAI began the year in a dominant position, with GPT-4 comfortably topping model leaderboards and dominant market share among enterprises experimenting with generative AI. But by mid-year, GPT-3.5-level performance had become the baseline. Anthropic’s Claude 3 Opus now surpasses GPT-4 on 10 key benchmarks, with wins ranging from narrow (86.8% for Opus vs. 86.4% for GPT-4 on a five-shot MMLU trial) to substantial (84.9% for Opus vs. 67.0% for GPT-4 on a key coding benchmark).
Soon, many models will soon meet or exceed the bar set by GPT-4, including open-source upstarts like Llama 3. When filtering the LMSys leaderboard for English-language prompts, Llama 3 70B claims the second spot, trailing only the latest version of GPT-4. Some AI builders on Twitter suggest that the gap between these two models is practically nonexistent. There’s even speculation that Llama 3 400B, which is still undergoing training, will perform on par with the eagerly anticipated GPT-5.
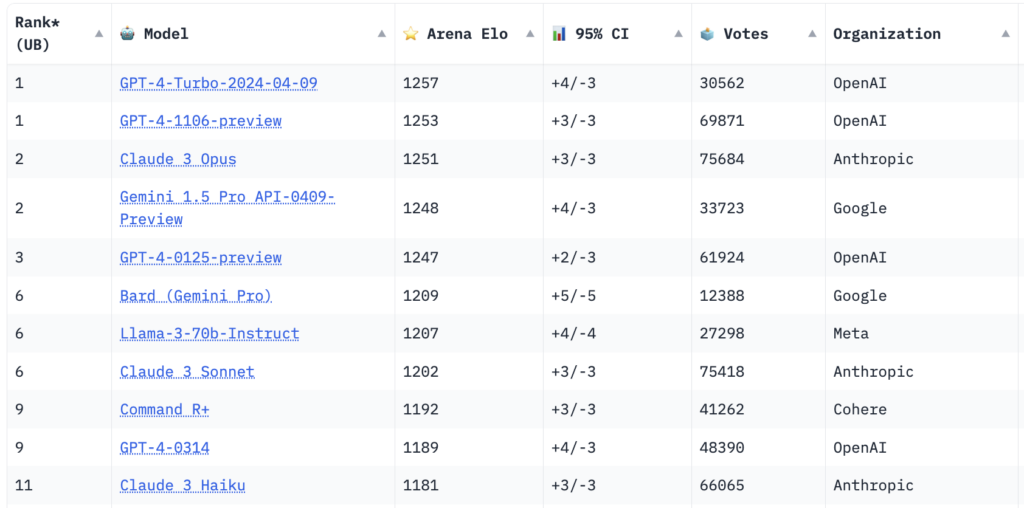
The ascent of open-source AI was arguably 2023’s most exciting development. While OpenAI once seemed untouchable, alternatives like Llama 3, Databricks’ DBRX, and Mistral are achieving exceptional results with fewer parameters and lower compute costs. As open- and closed-source model performance converges, both enterprises and app developers stand to benefit immensely.
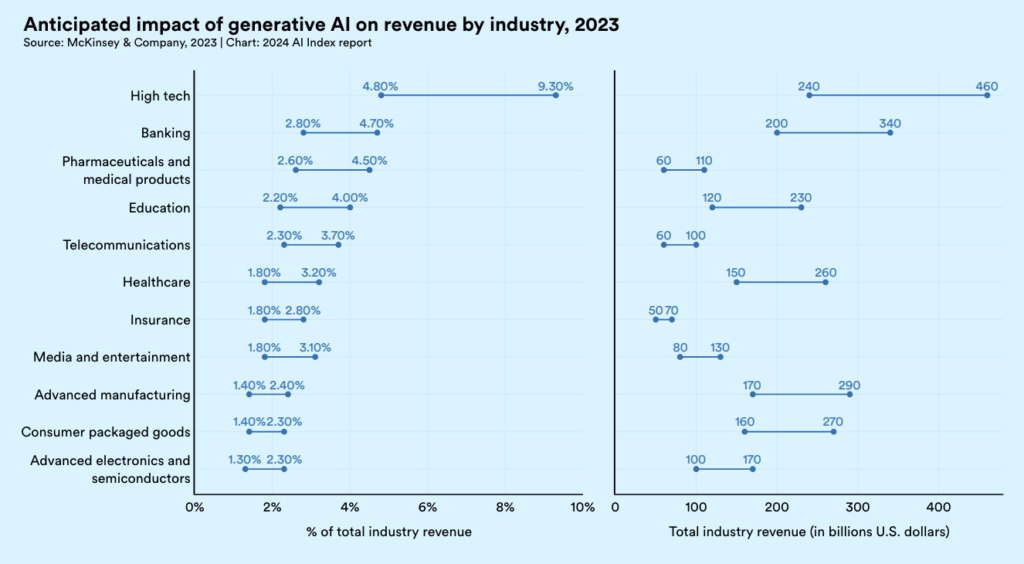
This rapid democratization of AI unfolded against a backdrop of growing enterprise adoption and investment. As generative AI pilots began to demonstrate real value, both enterprise budgets and use cases soared. A recent survey by a16z found that enterprises invested an average of $7 million in generative AI in 2023, with nearly all respondents reporting promising early results. The majority plan to increase their generative AI investments by 2-5x in 2024. McKinsey estimates that generative AI alone could potentially boost revenues in the high-tech sector by up to 9%, or nearly a half trillion dollars, in 2024. Importantly, these initiatives are transitioning from experimental “innovation” budgets to core software expenses.
2024: Inference on the rise
As we settle into 2024, the focus in enterprise AI is shifting from training to inference—the process of putting generative models to use in real-world applications. This shift is evident in the recent quarterly earnings reports from tech giants like Nvidia and Microsoft. Nvidia’s CFO revealed that 40% of their data center revenue in 2023 came from AI inference—a figure that we can expect to climb significantly higher in the coming year.
As I detailed in a recent post, inference presents a unique set of challenges compared to training, requiring companies to weigh a new set of considerations as they deploy generative AI applications at scale. These include:
> Latency: When running inference, low latency and high throughput are crucial, as applications must respond quickly to user requests. Training can afford to take longer since it usually occurs offline.
> Scaling: Production workloads can be highly variable, requiring an infrastructure that can dynamically adapt to fluctuating demand. While training also benefits from scalability, its resource requirements are generally more predictable.
> Multiple environments: Inference workloads need to be able to run in a wide range of environments, from cloud platforms to edge devices, each of which comes with its own set of constraints and considerations. Training, on the other hand, typically takes place in more centralized and standardized settings.
> Cost: While the price tag of training generative models is already staggering, these costs pale in comparison to the ongoing expense of inference at scale. The weekly cost of running ChatGPT for inference reportedly exceeds the entire cost of training the model. Training costs tend to be more predictable and manageable, typically involving one-time or periodic investments.
As businesses refine their AI strategies based on these factors, they’re increasingly relying on multiple models, even for the same feature. The emerging best practice is to design AI applications for maximum optionality by enabling easy switching between models, often with just a simple API change. This “model garden” approach allows enterprises to tailor solutions to specific use cases based on performance-cost tradeoffs, avoid vendor lock-in (a painful lesson learned during the cloud era), and capitalize on advances as the field continues to charge forward.
Despite the benefits of using multiple models, navigating the complexities of model deployment and optimization presents a daunting challenge for most businesses. According to a16z, implementation was one of, if not the, biggest areas of enterprise AI spend in 2023. This underscores the pressing need for solutions that streamline the process of deploying and optimizing AI models in production.
In response to this need, startups are developing “inference-as-a-service” platforms that abstract away much of this complexity. These platforms allow developers to easily combine and iterate on different permutations of models, clouds, and chips to strike the right balance of cost, performance, and efficiency for their use cases. Early movers in this space, like Modal, Baseten, and Replicate, are already gaining significant traction, but the market remains largely an open playing field.
2025: Three emerging trends
As we look ahead to 2025, I anticipate three further shifts in the enterprise AI landscape: a move from training ever-larger models to designing compound AI systems, an intensifying focus on AI observability and evals, and the emergence of credible alternatives to the transformer architecture. Each builds on the expanding role of inference.
1. Compound AI systems
Rather than relying on monolithic models to handle complex tasks end-to-end, the cutting edge of AI development is embracing a modular, system-level engineering approach. These compound AI systems employ multiple models that work together in iterative, looped processes, coordinating with each other and drawing on external tools to evaluate, refine, and improve their own results. By breaking down a large task into a series of subtasks, this approach allows builders to better optimize and troubleshoot each subtask, leading to higher overall performance.
Researchers at the Berkeley Artificial Intelligence Research (BAIR) lab, including B2BaCEO podcast guests Ali Ghodsi, Naveen Rao, and Matei Zaharia, are at the forefront of this shift. Their work has already demonstrated that compound AI systems can outperform individual models, even with far less training data and compute.
Consider the example they provide: while the best coding model today might solve problems 30% of the time, simply tripling its training budget may only bump up that success rate to 35%. By contrast, a multipart system like Google’s AlphaCode 2, which combines multiple LLMs with an advanced search and reranking mechanism, can achieve 80+ percentile coding performance using current models.
To again paraphrase BAIR, compound AI systems offer several advantages over single, static models. Iterating on system design is much faster and less expensive than training runs. Modular systems also allow developers to dynamically incorporate up-to-date information, enforce granular access controls on sensitive data, more reliably ensure that models behave as intended, and flexibly adjust performance and cost profiles to suit different use cases. These qualities are key for enterprise applications, where reliability, security, and cost-efficiency are mission critical.
Along with AlphaCode 2, other early examples of this approach, such as LLM Debate and CoT-SC,are showing strong results. A recent study investigated the “scaling laws” of LLM agents using the following method: feed a question to one or more agents, generate multiple answers, then take a majority vote. The results show that simply adding more agents leads to better performance across a wide range of benchmarks, even without advanced methods like chain-of-thought prompting and multi-agent collaboration frameworks.
While researchers used to report results from a single model call, they’re now making use of more sophisticated inference strategies. Microsoft beat GPT-4 on medical exams by 9% using a prompt chaining approach with an ensemble of models. Google’s Gemini launch post measured its MMLU benchmark score using a CoT@32 inference strategy that calls the model 32 times, causing some to question the fairness of comparing this result to a 5-shot prompt to GPT-4.
These developments underscore the growing importance of inference. As Andrew Ng explains, today’s LLMs create output that’s largely intended for human users. Yet, in compound AI systems, models call tools, create and execute multi-step plans, coordinate with other models, and iteratively reflect on and improve their outputs. All this behind-the-scenes work means that compound AI systems can generate 100,000s of tokens before returning any output to a human user. Under these conditions, sluggish inference can quickly become a chokepoint.
We’re still in the early days of figuring out how to build, optimize, and run compound AI systems. Frameworks like Stanford’s DSPy are helping researchers make progress on each of these fronts. AI “gateways” and routers, which I discussed this fall with Robert Nishihara, are also gaining traction. I expect to see more frameworks and best practices emerge in this space over the coming year.
2. Observability and evals
Today, checking if a generative model is working well often comes down to “vibes.” Needless to say, while this may work for casual developers and low-stakes tasks, it falls short for enterprises. The challenge of making sure models behave as intended will only become even thornier as we move from standalone models to compound AI systems, where interactions among models can yield unexpected and hard-to-predict results. Thankfully, faster inference will make running evals easier. Many startups, including our portfolio company Arize, are working on this problem, but it’s far from solved.
3. New model architectures
While transformers currently dominate, several alternative architectures are showing early promise, particularly when it comes to compute efficiency and scalability. This makes them potentially much better for high-inference workloads. A few that the enterprise team and I are watching, and which we plan to explore in an upcoming blog post, include:
> State-space models: By contrast to transformers, SSMs like Mamba, Striped Hyena, and Cartesia scale subquadratically with sequence length. Using techniques such as local attention mechanisms and logarithmic-sparsity patterns, models like Mamba, Striped Hyena, Longformer, and LogSparse can handle long sequences much more efficiently. This makes them well-suited for tasks that involve vast amounts of data, such as video processing and genomic sequence analysis.
> Large graphical models: Our portfolio company, Ikigai, is developing LGMs that excel at handling structured data, capturing temporal dependencies and complex relationships that are not easily modeled by other types of neural networks. LGMs have shown to be especially effective at analyzing time-series data, making them potentially invaluable for use cases across finance, forecasting, and logistics.
> Receptance Weighted Key Value (RWKV) models: These models take a hybrid approach, combining the parallelizable training of transformers with the linear scaling in memory and compute requirements of recurrent neural networks (RNNs). This allows them to achieve comparable performance to transformers on language modeling tasks while being markedly more efficient during inference.
Final thoughts
My main advice for AI-focused founders?
Build for where models will be in 1-2 years, not just where they are today. Bake the challenges of inference at scale into your roadmap. And don’t just think in terms of prompting one mega model and getting an answer back. Plan for the iterative systems design, engineering, and monitoring work needed to make your AI product perform the proverbial “10x better” than existing alternatives.
1. Compound AI systems
Published on April 26, 2024
Written by Foundation Capital
