Why 2024 Will Be the Year of Inference
02.22.2024 | By: Ashu Garg, Vinay Iyengar
In 2023, we saw LLMs near expert-level performance on the MMLU (massive multitask language understanding) benchmark — a test designed to evaluate models on subjects including STEM and social sciences from the elementary to expert level.
Of course, the MMLU has its blindspots. But what’s clearly visible is the rapid development of generative AI in the last few years, with the release of Open AI’s GPT family of models, Google’s PaLM and Gemini, as well as open source alternatives like LLaMa and Mixtral. With these recent performance improvements, we believe that LLMs will now be able to automate large swathes of knowledge work that AI previously couldn’t touch.
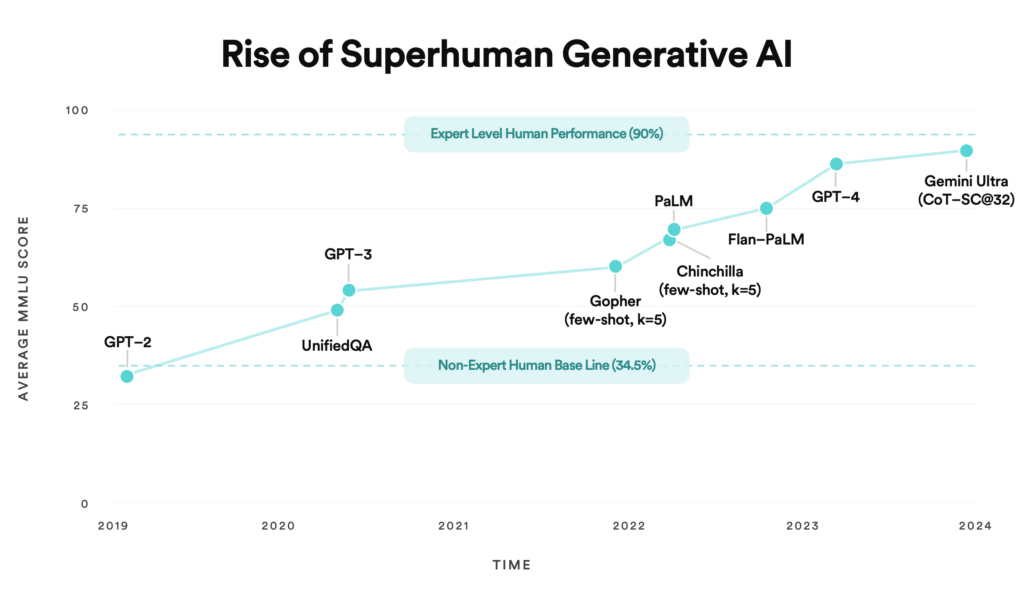
The performance of pre-trained models signals the training era is over. We believe 2024 will be the year of LLM inference — developers taking models and putting them into production for real world applications.
Yet doing so today is time-consuming and expensive. Companies need to containerize and quantize a model, find the optimal infrastructure to host it (especially given the GPU shortage today), and serve it in an optimized manner, which takes weeks and sometimes months of engineering time. Moreover, inference is incredibly costly; it is estimated that OpenAI spends more per week on ChatGPT inference than on the entire cost of training the model.
These problems broadly present a huge market opportunity. There is a massive prize available for startups who can make the process of deploying models in production easier, more accurate, cheaper, and faster.
The Fragmenting Infrastructure Ecosystem
Improved model performance has created a gold rush of sorts — and we’re seeing a number of “picks and shovels” solutions when it comes to building generative AI apps.
The emergence of new model architectures purpose-built for specific tasks (image generation, video generation, 3D asset creation, or domain-specific tasks like writing code) gives developers a number of blocks with which to build applications. However, each of these models and modalities have subtleties around training and serving that increase complexity for developers. For example, the workflow to finetune, deploy, and evaluate a text-to-image model will differ substantially from the workflow for a coding copilot.
We’re also seeing the rise of new cloud providers specifically focused on GPUs and LLMs. The large cloud service providers have been unable to keep up with demand for GPUs and we have seen an unbundling of sorts in the industry. Companies like Lambda Labs and Coreweave have emerged as viable alternatives to the big cloud providers with more GPU access and generative AI-specific support.
Given the ravenous demand for GPUs and the meteoric growth of NVIDIA (now worth more than Google and Amazon), many companies, from tech giants like AWS and Meta to new startups, are entering the market and building AI ASICs (application specific integrated circuits). Many of these are purpose-built for optimizing model inference as opposed to model training. These include AWS’ Inferentia chip, AMD’s MI300X accelerator and Intel’s Gaudi 2. While NVIDIA will remain a big player here, we anticipate many new entrants coming for their lunch and a wide range of chip options available for those serving models.
This fragmentation has two sides. The emergence of inference-specific clouds and chips will likely reduce inference costs longer term. But it’ll also increase choice, and therefore complexity, for developers.
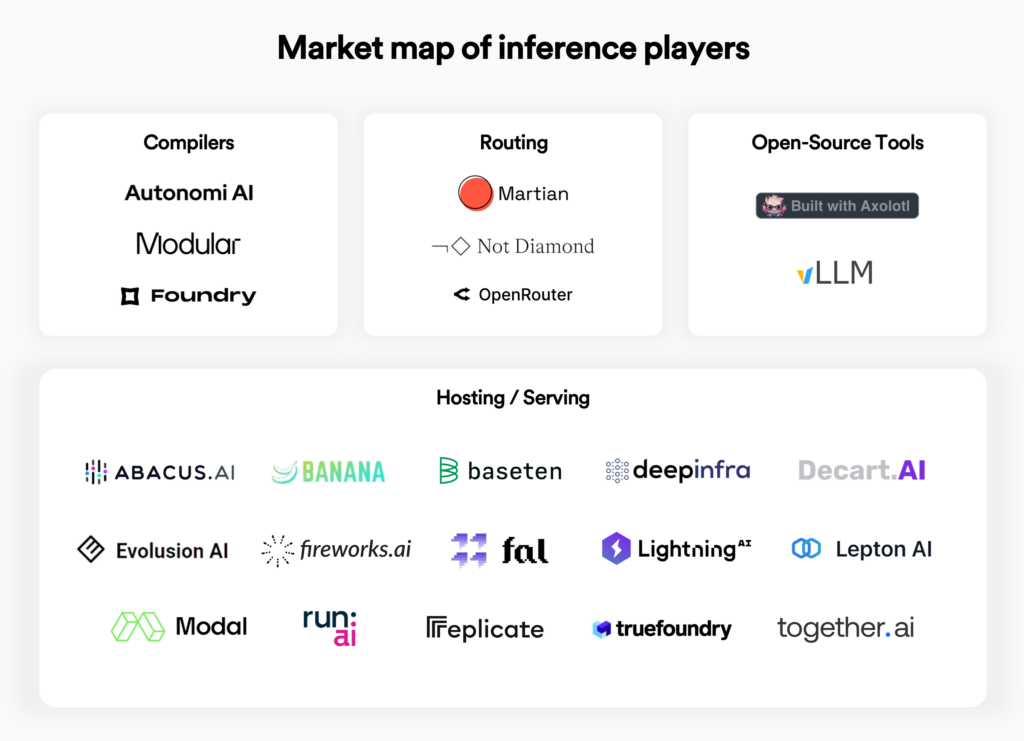
We see a future that is multi-model, multi-modal, multi-cloud, and multi-chip. The diagram below shows the three distinct layers of the generative AI inference stack that are emerging.

Inference Isn’t One-Size-Fits-All
What makes inference all the more complex is that different user personas are optimizing across a variety of parameters.
Some care about the lowest cost. Others care about having the best user experience possible. Some want the most accurate answers for a given query. Several want latency to be as low as possible. Across these four dimensions, there becomes a number of configurations that developers can use and levers they can pull across the three layers of the stack. As an example, a given image generation model running on a specific cloud provider and chip architecture may provide a highly accurate and low latency experience, but could cost up to 2x per inference request compared with another cloud and chip configuration that sacrifices some latency and accuracy. There is no one-size-fits-all answer.
Startups are stepping in to tame this fragmentation complexity. Some focus on completely abstracting away complexity for the developer and taking care of all hosting needs, like early leaders Baseten and Modal. Others consider themselves to be new-age compilers, providing more control and flexibility for the developer. An emerging category of startup is LLM routers, which are able to intelligently route prompts to different models based on some optimization criteria. Finally, there are a few emerging open source projects that bill themselves as the optimal inference engines.
Predictions for the Inference Ecosystem
As the inference market continues to evolve, here’s what we think will define startups of this era.
Fragmentation will continue
Developers will have many options around the types of models they put into production (whether open or closed source). They can also choose the underlying cloud provider that hosts these models, and the actual chips that run these models. Enterprises and startups alike are experimenting with these setups, but lack the ability to understand the tradeoffs that exist around performance, cost, and latency. Their developers are operating blind. Any startup that can offer visibility across the stack will have immediate value and provide an interesting wedge to offer inference-related products like model finetuning, experimentation, hosting or observability.
Extensibility matters
Like with many low and no-code tools in the past, we believe that offering a fine balance between ease-of-use and extensibility will be key for startups in the space. Especially for enterprise buyers, there is little appetite for tools that completely abstract away the subtleties of putting these models in production, as each enterprise wants control over customizing the final end-user experience. At the same time, many legacy enterprises don’t have the team to configure this all in-house. Companies that can tow this line effectively will be hugely valuable.
The open source hype is real
Underlying our core thesis in the space is a belief that open source models like Meta’s LlaMa or Mistral’s Mixtral will be viable alternatives to closed source providers like OpenAI and Anthropic. Not only are these models reaching performance parity with their closed source peers, but because of privacy, cost, latency and fine-tunability, many enterprises are opting for the open source path. This will continue to create an opportunity for startups that help end users fine-tune and productionize these models. Companies like Modal, Baseten, and Replicate have already reached substantial scale focused on just this segment of the market.
Startups will rise
Inference startups face an uphill battle given how intensely competitive the market is, but we believe that several decacorns will emerge in the coming decade. The model, cloud, and chip providers are inherently incentivized to support their own platforms and ecosystems. What this means in practice is there is a massive opportunity—we believe in the billions of dollars in ARR—to build the neutral, third-party, single-pane-of-glass to manage inference across this increasingly complex stack.
We strongly believe that inference is the biggest opportunity since the advent of cloud computing.
In the coming decade, every enterprise will have multiple generative AI models running in production, whether built in-house or via a third-party vendor. The complexity and cost of such an undertaking will create a massive market opportunity for entrepreneurs building in the space and we couldn’t be more excited about the innovation ahead.
Published on 01.31.2023
Written by Foundation Capital
