What to Look for in Next-Generation APM Solutions
February 4, 2020
Steve Vassallo
Following Splunk’s acquisition of SignalFx last year, the obvious question for many venture investors has been, What’s next in the application-monitoring (APM) world? As an ex-operator, I decided to spend time with developers, IT teams, founders, and industry practitioners to understand firsthand their unmet needs. What I found is that their needs are immense, as the rate of adoption of the modern stack (e.g., containers, service meshes, RPC layer, serverless) is steadily outpacing APM solutions that were born and tailored for the service-native era. For example, one VP of engineering of a growth-stage tech company told me that, six months after they’d adopted Kubernetes, he was stunned at how their Datadog bill rapidly ramped up from around $2000/month to more than $10,000/month, in only a few months.
Today, this challenge is not just limited to technology companies. It also impacts Fortune 2000 enterprises, which are all undergoing digital transformation and the rapid software development cycles that comes along with it. As a result, there is an increase in the heterogeneity of enterprises created by multi-cloud hybrid environments and web-scale architectures. This makes it tougher than ever to monitor systems holistically and debug issues in a timely manner.
In the past, for every infrastructure wave, a new class of APM products emerged to fill this gap in the market. Recognizing this gap at a crucial time was the secret to their success. Let’s review the recent history.
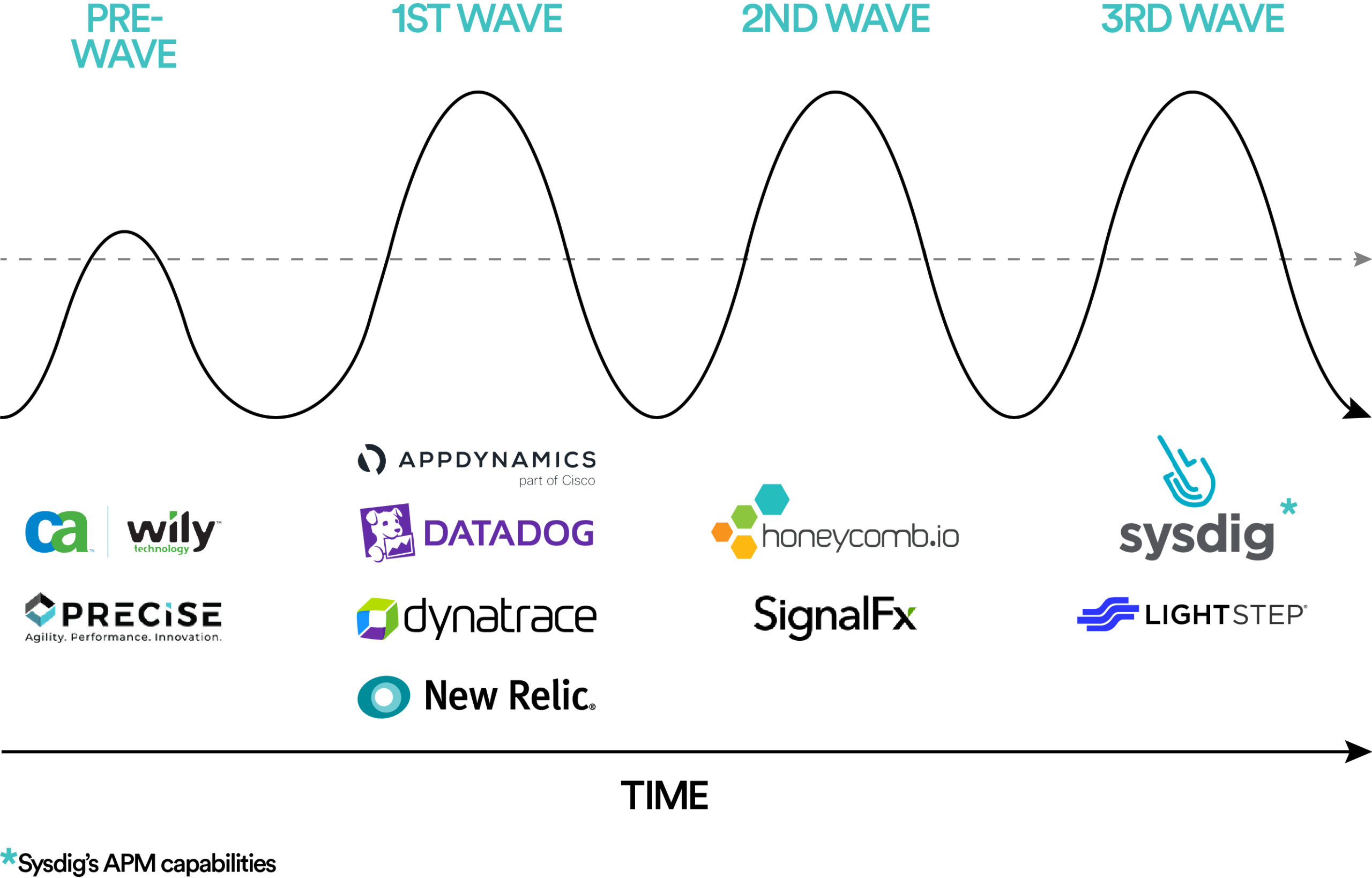
Wave I: From mainframes to distributed systems
- Market Gap. With a high volume of business-critical applications being deployed across distributed environments (virtualized and/or hybrid cloud), there was a need to measure application performance, while allowing admins to dig into the root-causes of performance issues.
- AppDynamics was among the first to deploy agents for application mapping, transaction-flow monitoring, and code-level diagnostics across all aspects of their customers’ distributed computing environments.
- Datadog developed an integrated view of tools and services used by IT teams with an initial focus on infrastructure monitoring and gradually added APM and log management capabilities. In addition, Datadog leveraged the first generation of cloud adoption by focusing on customers who had started to build applications using cloud providers’ APIs and services.
Wave II: From distributed systems to cloud-native
- Market Gap. As enterprises deployed dynamic cloud-native applications, there was a need to transition from component-level monitoring to understanding system-wide anomalies.
- SignalFx introduced the idea of streaming vs. batch data, making it possible to alert within seconds through real-time monitoring across cloud, on-premise, and hybrid environments. Additionally, SignalFx’s tail-based sampling vs. head sampling AIOps approach allowed more relevant traces to be captured.
- Honeycomb’s value proposition was targeted towards timely debugging and effective root-cause analysis of complex production issues through a cloud-first lens.
Wave III: From cloud native to service native
- Market Gap. With a growing adoption of micro services and a surge in application and infrastructure data, it has become harder than ever to manage the complexity of the emerging infrastructure stack and to troubleshoot issues in a timely fashion.
- Lightstep’s agentless open-tracing approach has been the first service-native approach that can manage the scale and complexity of microservices architecture.
- Sysdig’s approach to container monitoring utilizes run-time security and forensics through an open-source design. Over time, Sysdig has added eBPF instrumentation to offer deep visibility for cloud native and container environments.
As Wave III companies attempt to address the market gap for modern architectures and commercializing agentless technologies, Wave I and Wave II are trying to keep up by expanding their offerings in open-source agentless technologies. Legacy companies like AppDynamics, New Relic, and SignalFx, for example, have adopted open-source distributed tracing, a CNCF project co-created by the founder of LightStep. But the APM story isn’t written yet. I still see a wide-open window of opportunity for truly next-generation APM solutions built for the service-native world. Let me suggest several directions for those interested in building these solutions.
![]()
1. Breaking data silos by cross navigating the three pillars of APM. Currently logs, metrics, and traces operate in silos. Breaking those silos and being able to correlate and cross-navigate the three pillars of APM is where we need to go.
2. Scaling for the service native world through one of the various technically differentiated approaches. Better data visualization and data collection no longer differentiate APM solutions. Next-generation solutions will be differentiated by their ability to scale for the service-native world and predictive outlier detection, beyond faster debugging capabilities, to keep a finger on the customer’s pulse. Various approaches could include creating one of the following:
- Agentless architecture – While distributed tracing has nascent community activity (e.g., opentracing, zipkin, X-Trace), eBPF tracing or a sidecar approach are relatively newer agentless approaches to monitor systems that could be implemented with minimal instrumentation efforts.
- Observability fabric by aggregating public cloud and open source monitoring tools – Some emerging startups (e.g. Grafana Labs and Chronosphere) have taken a step in this direction by cobbling together open source tools like Loki, Prometheus, Carbon or StatsD to utilize the large amounts of data being produced due to the growing complexity of the architecture. A next-generation solution would stitch together tools across public-cloud providers and open-source to be developer-centric and help developers see granular value with zero instrumentation friction.
Either of these approaches would go hand-in-hand with faster debugging capabilities and predictive outlier detection, to understand system-health anomalies. While incumbent APMs over-index on infrastructure metrics, an ideal next-generation solution would correlate end-user health metrics with back-end metrics to give an early assessment of issues that could have a direct business impact. In addition, coupled with machine learning, the anomalies can be notified through real-time alerts.
3. Building developer-centric products fueled by a strong product and technology DNA. While strong technology background is table-stakes, the team, especially founders, should have a combination of strong product and technology DNA to build the next-generation APM product that developers would like to use.
4. Enabling effective product led go-to-market (GTM) through minimal instrumentation needs and “out-of-the-box” health metrics. Product-led GTM would be effective if the product can be deployed quickly by minimizing instrumentation efforts and demonstrate immediate value by providing “out-of-the-box” health metrics. This approach would help developers see and appreciate the value vs. effort trade-off across APM products very quickly.
5. Evangelizing stronger standards to help expedite adoption of new service native technologies. While enterprises are open-heartedly embracing modern architectures, we need stronger standards and better practices to work with these technologies to make them easy to observe and debug. APMs should not just provide tools to monitor our services, they should also dictate how we design our services from the outset.
These are just a few ways that new products can emerge, based on my on-the-ground conversations and deep dive into market needs. The future of next-generation APM is full of exciting potential for startups. At Foundation Capital, we are constantly looking to see how new solutions in this space are pushing the envelope. If you’re a founder who’s riding the current or next APM, we’d love to talk to you!