NVIDIA’s “AI Factory” Bet
03.29.2025 | By: Ashu Garg

I break down NVIDIA’s push to own the full AI stack – from silicon to software – and explore what it means for startups building in the era of agentic AI.
Last week, NVIDIA hosted its annual GTC developer conference in San Jose – drawing 25,000 attendees to the SAP Center for what CEO Jensen Huang dubbed the “Superbowl of AI.”
Much of the coverage focused on the headlines: new chips, robotics demos, and performance gains. But what stood out to me more than NVIDIA’s roadmap was the broader case Jensen was making for how computing is being reconfigured – and what this means for how and where value will be created in the AI era.
Jensen calls it the “AI factory.”
The phrase isn’t just metaphoric. It’s meant to reframe how we think about compute infrastructure – shifting it from a cost center to a production system. In manufacturing, a factory transforms raw materials into finished goods through a structured, optimized process. The economic value lies in throughput and efficiency: how much output can be generated from each unit of input, whether labor, energy, or capital.
Jensen argues that the same logic now applies to AI infrastructure. The inputs to these modern factories are electricity and data. The outputs are tokens – the atomic units of prediction, reasoning, and generation that power AI systems. The new unit of productivity is tokens per second per watt: a measure not only of how fast chips are, but of how efficiently intelligence can be produced at scale.
This is more than a branding exercise. It’s a redefinition of what a data center is for. Traditional data centers are designed to retrieve pre-written software and execute it deterministically. AI factories are built to generate software on the fly. The logic is not fixed but emergent. As Jensen put it: “In the past, we wrote the software and ran it on computers. In the future, the computer is going to generate the tokens for the software.”
This shift – from “retrieval-based computing” to “generative computing” – has defined the post-ChatGPT tech landscape. This year’s GTC helped me sharpen my view of where it’s heading next. NVIDIA’s announcements around inference orchestration, power efficiency, and full-stack design reflect the growing complexity of these “AI factories” – and the need to manage them as tightly integrated, end-to-end systems.
Positioning data centers as AI factories signals a new set of priorities for NVIDIA. It elevates power as the primary constraint. It treats throughput and latency as a joint optimization problem. And it positions inference – not training – as the dominant workload of the coming decade.
It also helps clarify NVIDIA’s strategy. The company isn’t just selling GPUs anymore. It’s selling the full assembly line: silicon, networking, memory, software, and scheduling systems. And it’s doing so with the logic of industrial systems design – where the key to scale isn’t just raw performance, but system-level optimization and control.
This month, I want to unpack three key themes from GTC that bring the AI factory concept into focus: how it reframes compute economics, how infrastructure is evolving to support it, and where the biggest opportunities lie for both incumbents and builders.
Three themes from GTC
1. Cheaper inference will drive exponential demand for tokens
Taking aim at the fears stoked by DeepSeek, Jensen repeatedly emphasized that we’re dramatically underestimating how much compute the next generation of AI models will require.
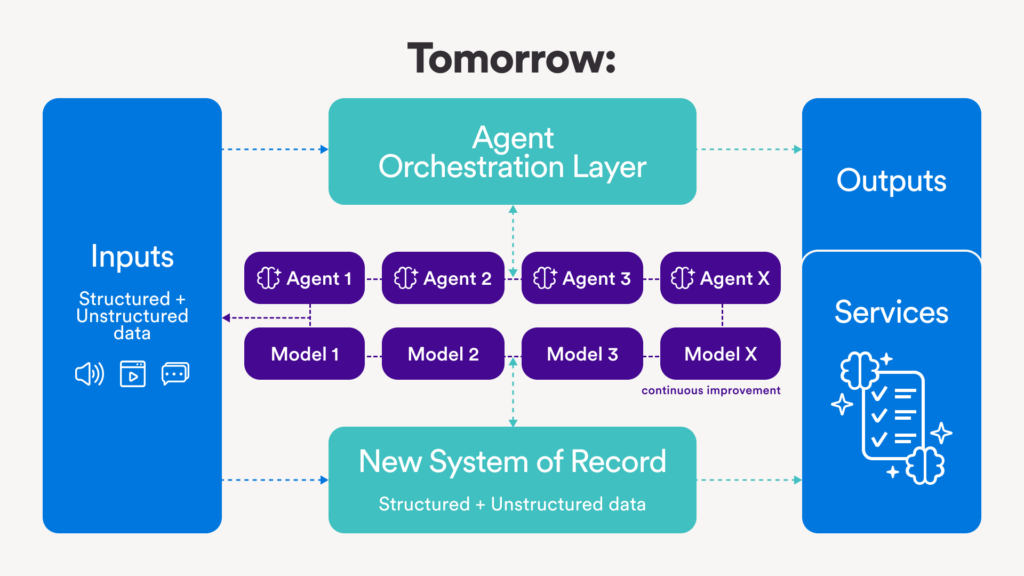
In his analysis, we’re moving from a world governed by a single scaling law (pre-training) to one shaped by three: pre-training, post-training, and test-time inference. Reasoning models require 20x more tokens and 150x more compute per query than traditional LLMs. Today’s frontier models already ingest over 100T tokens during training, and enterprise applications are projected to run 100s of millions of agentic queries per month.
This rising demand underpins NVIDIA’s ambitious roadmap: Blackwell Ultra later this year, Rubin in 2026, and Rubin Ultra after that – all built to accommodate what Jensen calls a “hyper-accelerated” token economy.
Jensen’s case rests on a long-established but newly resonant economic principle: Jevons paradox – the idea that when a resource becomes cheaper and more efficient, we consume more of it.
NVIDIA is applying this logic to AI tokens. As inference costs fall, applications that were once too expensive – like persistent agents and multimodal reasoning – suddenly make economic sense. The result, in theory, is a flywheel: more efficiency = more tokens = more compute = more NVIDIA. “The more you save, the more you make,” as Jensen puts it.
That’s the bull case. The counterpoint isn’t that Jevons is wrong – it’s whether demand is elastic enough to justify NVIDIA’s growth projections. If enterprises pull back on AI spending, if the infrastructure required to deploy new workloads is slow to materialize, or if marginal utility flattens as AI saturates certain use cases, NVIDIA’s assumptions may overestimate the slope of the compute demand curve.
There are other flaws in this framing. Open-source models, from Alibaba to DeepSeek, are rapidly improving and driving token prices down. If tokens become commodities, and “good-enough” models can run efficiently without large clusters of high-end GPUs, the economics of token generation at scale could erode faster than NVIDIA expects.
Still, the core thesis is compelling – and consistent with what I’m hearing from founders and teams in the field. Inference costs are central to product and infra decisions in a way they weren’t 12 months ago. The key question is no longer whether demand will grow – it’s where, how quickly, and who will capture it.
2. System-level orchestration is a strategic priority
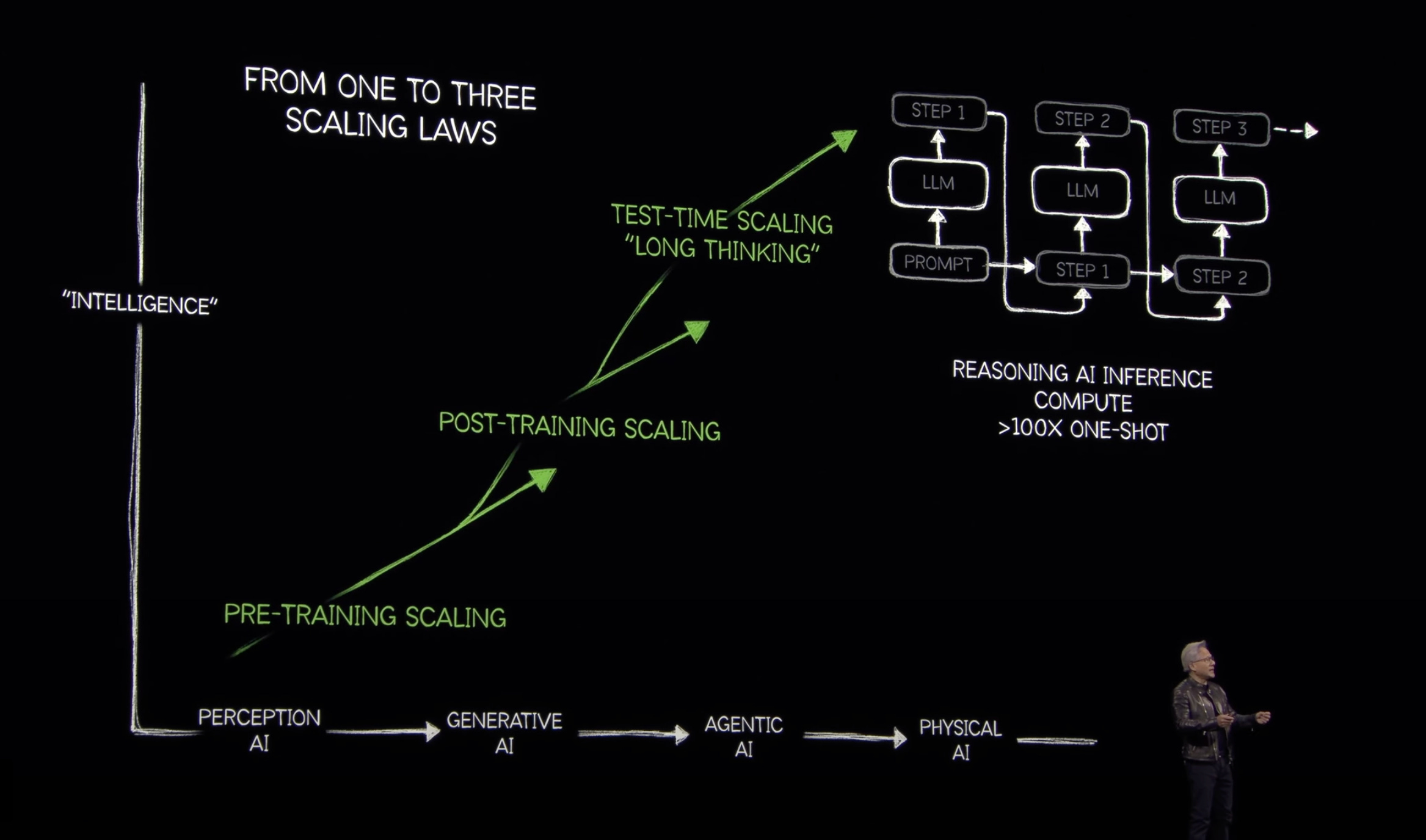
A more technical – but equally important – part of Jensen’s keynote addressed the “Pareto Frontier” in AI computing: the tradeoff between system-wide throughput (how many tokens you can generate per second) and per-user responsiveness (how quickly any one query returns a result).
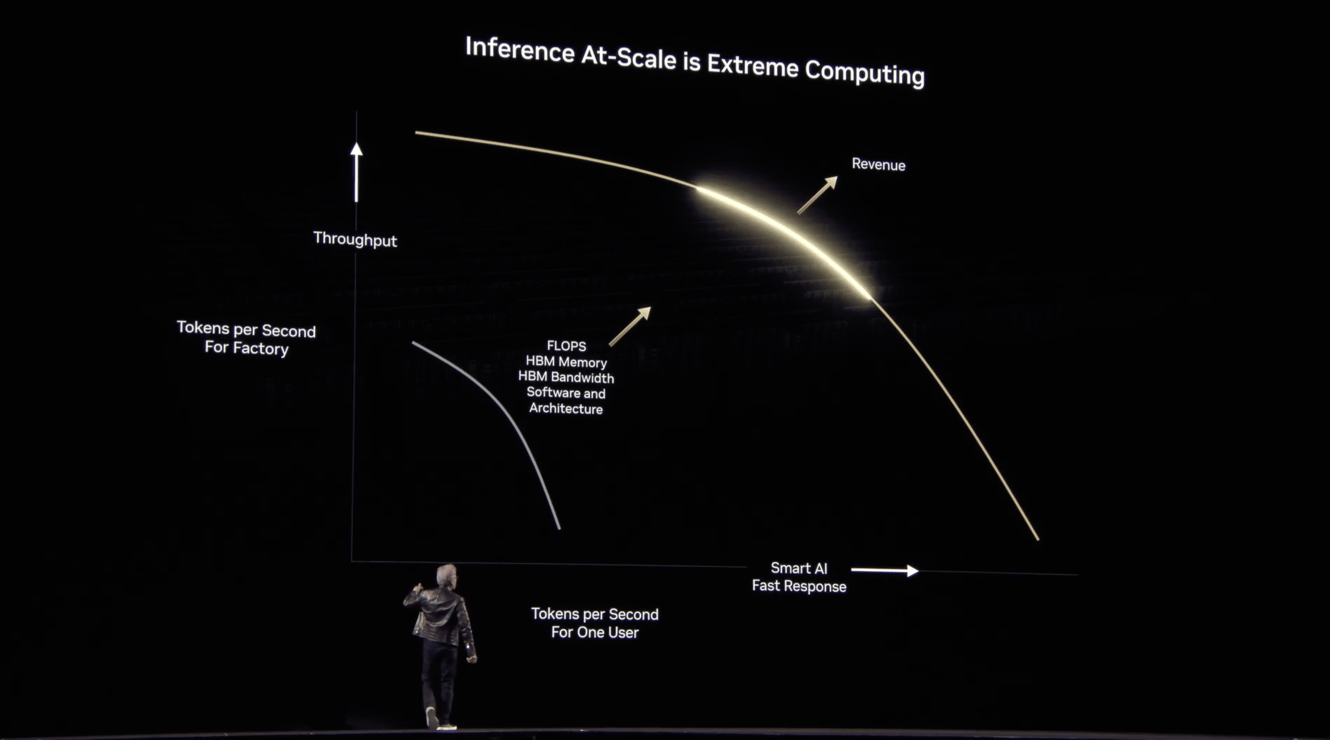
This is not a new problem. But with the rise of reasoning models – and their more complex execution patterns – it’s become more urgent. These systems operate in two distinct stages: prefill and decode. Prefill is the “thinking” phase, where models ingest context and plan a response. It’s highly parallel and FLOPS-intensive but doesn’t output much. Decode is the “speaking” phase – where the model generates tokens – which demands high memory bandwidth and low latency. What makes this hard is that infrastructure optimized for one phase often underperforms on the other.
NVIDIA’s response is Dynamo, a real-time orchestration layer that acts like the AI factory’s “operating system” – dynamically allocating GPU resources between prefill and decode. It turns a hard constraint (throughput vs. latency) into a tunable system-level parameter, enabling more responsive, efficient token generation at scale. As Ben Thompson summed up: “ASICs have to pick a point on the curve, but GPUs can cover the entire curve.”
This kind of system-level control is not exclusive to NVIDIA. Hyperscalers like Microsoft and Google are building tightly integrated software stacks for their custom chips. AMD is a major player, and startups like Cerebras and Groq are pursuing alternative architectures. And open-source projects like vLLM are improving fast – making it easier to serve models efficiently. Together, these efforts point to a more open and flexible future, where the dominant “AI OS” may not come from a single company, but from a broader ecosystem.
3. Agentic AI is reshaping infrastructure requirements
Another clear shift coming out of GTC was the move from single-shot prompts to agentic systems – software that can plan, reason, and act over extended periods.
NVIDIA introduced its Nemotron family of models (built on top of Llama and post-trained with DeepSeek-R1), designed for multi-step reasoning, tool use, and state persistence. It’s part of a broader trend: OpenAI’s “o1” series, Claude 3.7, and Gemini 2.5 are all racing to become the foundations for AI agents that can maintain memory, interact with APIs, and operate continuously.
This shift has major implications for infrastructure.
First, agents aren’t stateless. Unlike traditional LLMs, they need to remember what happened in previous turns, track their reasoning, and update context over time. Techniques like KV cache offloading help manage memory across longer sessions, but they’re just one piece of the puzzle.
Second, agent workloads are highly unpredictable. They may be idle one moment, then spike with tool calls or multi-step reasoning the next. NVIDIA’s Smart Router and GPU Planner address this issue by dynamically reallocating compute based on workload – but as agents become more complex, more flexible orchestration layers will be required.
Third, observability becomes critical. When agents are making decisions over time across multiple tools and contexts, it’s not enough to just log inputs and outputs. Developers need visibility into how decisions were made: how reasoning unfolded, what memory was accessed, what tools were called, and why. Without this, debugging and governance become impossible.
This is where platforms like Arize come in – helping developers trace, debug, and evaluate how agents make decisions. As agents connect to more tools and external systems, the integration layer becomes harder to track and control. Anthropic’s Model Context Protocol (MCP) – now adopted by OpenAI – deepens this integration by standardizing how models receive context and invoke tools. As agent workflows become more complex and interconnected, the integration layer effectively becomes a system of record: a critical source of truth that must be monitored, evaluated, and governed.
All of this creates meaningful surface area for startups. Just as Kubernetes and Docker redefined how distributed applications were built and operated, we now need infrastructure that can support the full lifecycle of AI agents. If this mirrors the trajectory of cloud-native software, open-source tooling is likely to define the standard – and NVIDIA may not be the one to own it.
Summing up: The bull and bear cases for NVIDIA
NVIDIA’s stock dipped around 4% after Jensen’s keynote. While the company’s progress is hard to argue with, investors are increasingly asking whether AI spending can keep scaling at the rate NVIDIA is counting on.
The bull case is that NVIDIA is going full-stack – chips, systems, software – and the performance leaps are significant. Blackwell reportedly delivers up to 40x the reasoning performance of Hopper, and early demand is strong, with 3.6M units ordered by major cloud and enterprise buyers. Combine that with NVIDIA’s moves into simulation, robotics, and enterprise tooling, and it’s easy to see how they could become the backbone of the modern computing stack.
Still, the bear case is becoming harder to ignore. AMD’s MI300X already matches or beats the H100 on some inference workloads, and its roadmap is moving fast. Meanwhile, startups like Cerebras are approaching the same challenges with different – and, for many use cases, more performant and efficient – architectures.
Another threat comes from NVIDIA’s own customers. Amazon’s Trainium chips reportedly run at a fraction of NVIDIA’s cost. Meta and Microsoft are scaling up their in-house chip efforts. When your largest customers are also trying to replace you, it’s hard to forecast long-term demand.
On top of all this is the broader macro uncertainty: tariffs, inflation, and real concerns about whether enterprises will hold up in a more cautious market. NVIDIA’s stock has fared better than most during recent volatility, but it’s still down over 18% year-to-date. It now trades at under 25x forward earnings, a steep discount from where it stood at last year’s GTC.
Implications for the broader tech ecosystem
Taken together, the core themes coming out of GTC – token economics, system-level orchestration, and the rise of agentic systems – signal changes in how AI is built, deployed, and monetized. And they carry ripple effects across the entire innovation ecosystem.
For hyperscalers and cloud providers, the AI factory formalizes a shift that’s already underway: the end of the general-purpose, commodity data center. Traditional data centers are designed to run any workload on standardized hardware. But AI’s massive power and performance requirements are driving the rise of specialized infrastructure – purpose-built for performance-per-watt. NVIDIA’s roadmap – featuring liquid cooling, rack-scale design, and co-packaged optics – is as much about energy as it is about silicon.
As NVIDIA’s vertically integrated stack continues to expand, cloud providers will need to move up the value chain. Differentiation will shift from raw compute to orchestration, integration, and developer experience. Enterprises will prioritize infrastructure that supports multi-model systems, integrates cleanly into their stack, and accelerates time-to-production.
For AI infrastructure startups, NVIDIA’s expanding footprint raises the familiar question: where can startups win? One answer is by pursuing what NVIDIA isn’t optimizing for – open, interoperable infrastructure and domain-specific solutions. Startups like Anyscale, built on open systems like Ray, are betting on this dynamic – prioritizing flexibility, developer control, cross-platform compatibility.
Speed-to-deployment is another underappreciated vector. Many enterprises know they need to adopt AI, but lack the internal tooling or expertise to move quickly. Startups that help them get from “AI strategy” to “AI in production” – whether through observability, orchestration, cost optimization, or governance – can create immediate value. And as the ecosystem diversifies, startups that bridge across accelerators, clouds, and deployment environments will be especially well-positioned.
For application-layer startups, the message is simple: now is the time to build. Infrastructure is maturing, and inference costs are falling. What was previously too expensive – state persistence, step-by-step reasoning, multimodal input – is now within reach. This opens the door to a new generation of agentic applications that reason, plan, and act – powering high-value use cases across research, knowledge work, customer support, and real-time decision-making.
Falling inference cost is only part of the story. As model performance converges, system design becomes the real differentiator. The winners at the application layer will be those who master the architecture of intelligence: how models are composed, how memory and feedback are managed, how outputs are verified and acted on, and how systems adapt to new context over time.
In our current AI moment, the product isn’t a model – it’s the system. The advantage belongs to those who can best imagine how to design and optimize it – and have the technical talent to make it real.
Published on March 28, 2025
Written by Ashu Garg