


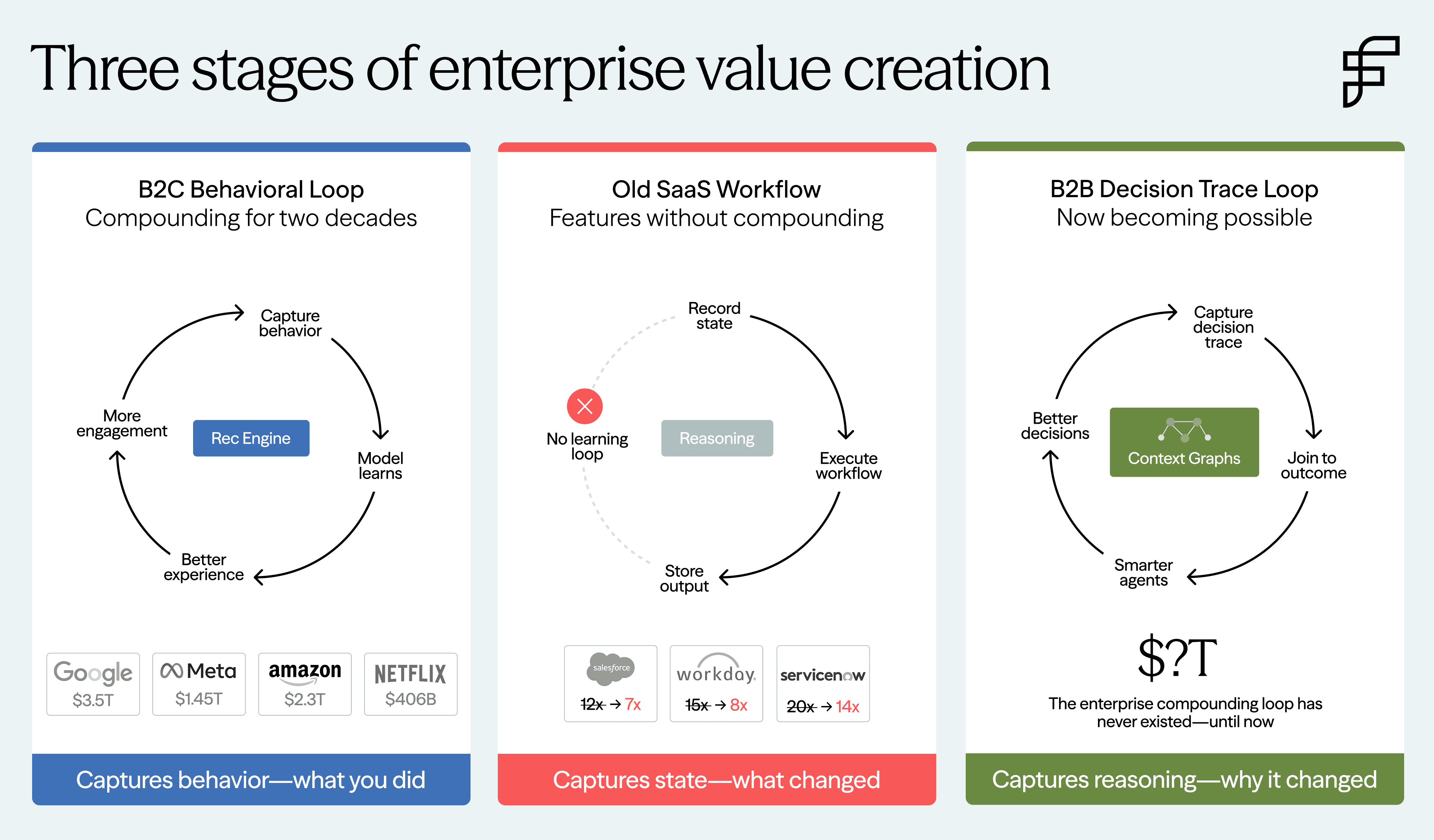
Consumer platforms built one of the most powerful business models of the last two decades around a compounding loop: every user interaction became a signal that improved the system. Netflix, Meta, Amazon, TikTok, and Google did not just record outcomes. They instrumented behavior with extraordinary granularity—what you clicked, what you ignored, what you hovered over, what you abandoned, what brought you back—and fed those signals into systems that learned. That loop—capture, learn, improve, capture again—became one of the great compounding assets of the internet era.
Enterprise software has never had an equivalent loop. Not because enterprise decisions are less frequent, but because they were harder to observe.
Consumer systems operate inside controlled interfaces where a single user acts within a product the company fully owns. Enterprise decisions are fundamentally different: they are multiplayer negotiations across sales, finance, legal, operations, security, and management—each carrying different incentives, different authority, and different constraints. Sales wants velocity. Finance wants margin. Legal wants precedent control. These decisions are negotiated, not merely clicked. To date, enterprises have lacked instrumentation of the reasoning that connected action to outcome.
B2C companies have been compounding behavioral signals for two decades. B2B companies largely have not. Now, for the first time, that is starting to change.
The old model is breaking
SaaS multiples have compressed because AI is commoditizing the feature layer that justified premium pricing. When an LLM can generate a competent first draft of almost any workflow, the value of "better UI on a known process" collapses — and companies whose moats were features, not data, are the ones being marked down. They built workflows but never built compounding loops
The question is what replaces features as the durable source of enterprise value. The answer is the compounding loop that enterprise software never had, built not on behavioral traces, but on decision traces.
What enterprise software actually captured, and what it missed
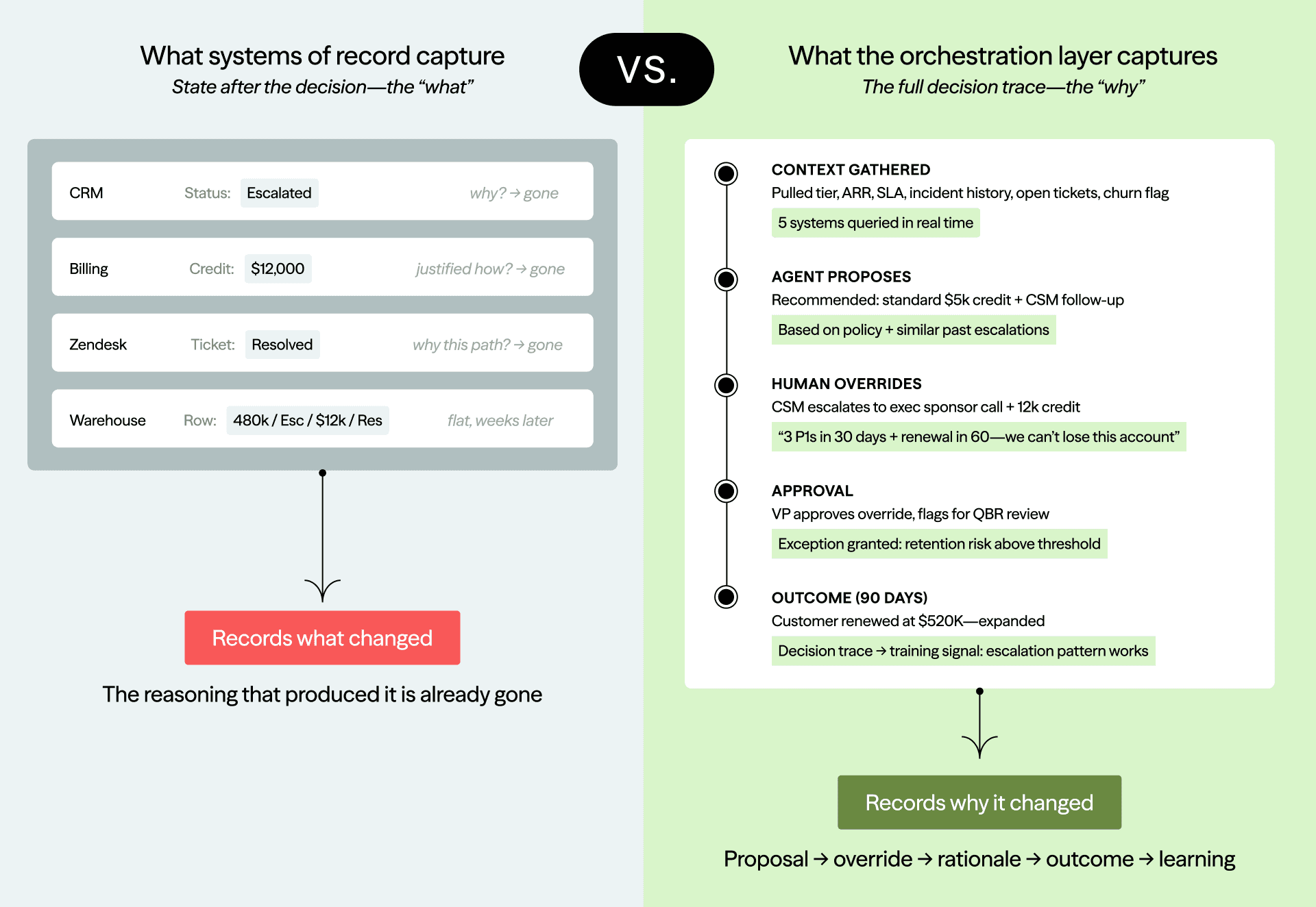
Enterprise systems were built to record end state, not reasoning. A discount field tells you the final number, not why that number was justified. A redlined contract tells you the final clause, not which fallback positions were rejected along the way. A resolved ticket tells you the incident is closed, not why one escalation path was chosen over another. Decision traces sit in that missing layer between event and outcome. A context graph is what happens when that layer becomes structured, queryable, and connected across systems, actors, and time.
The relevant signals were also sparse, fragmented, and embedded inside human workflows rather than captured as first-class telemetry. Enterprise decisions happened partly in a meeting, partly in someone's head, partly in an email thread, partly in a side conversation, and partly inside systems that did not talk to one another.
And there was no reason to store it. Decision data was treated as process exhaust—ephemeral, disposable—because no system existed that could learn from it. Even when fragments were captured, they rarely compounded. Companies had transcripts, email threads, comments, and approvals, but no practical way to extract structured decision artifacts from them, connect them across systems, and link them to outcomes. The raw material existed in pieces, but the loop did not.
What's changed
Enterprise work now lives on instrumentable surfaces. Work has become distributed and asynchronous. Decisions increasingly get made in comment threads, document suggestions, ticket histories, approval flows, and call recordings. Reasoning that once lived only in someone's head now leaves an increasingly rich trail in the workflow itself.
Language models make the unstructured data computable. For years, companies had transcripts, chat logs, document comments, and ticket histories, but these were mostly searchable, not learnable. Now an LLM can extract decision artifacts from them.. Language models do not eliminate the need for structure or evaluation, but they make it possible to turn previously inert collaboration data into something a system can reason over.
Agents create decision checkpoints automatically. This is the most important shift. Agents propose actions inside workflows, which humans approve, modify, or escalate. An agent drafts a pricing proposal; the sales rep adjusts the discount from 25% to 30% and adds a note: "competitive pressure from Vendor X, need to match their offer." That edit is a decision trace.
The model's proposal is a structured prior—what the system thought was right. The human's modification is the judgment signal—what actually matters that the model missed. As agents insert themselves into more workflows, more judgment is forced to become explicit through edits, approvals, exceptions, and overrides. The instrumentation is no longer optional. It is a byproduct of how the work gets done.
The strongest objection is that the most valuable judgment often never emits a trace—it lives in intuition, politics, memory, and side conversations. That objection is real, but the thesis does not require it to be false. We do not need all judgment captured; we need enough of the repeated, high-value decisions to become explicit that the system can start learning from them. Agent-mediated workflows are crossing that threshold by turning silent expertise into observable corrections: every time a human edits an agent's proposal, what was once tacit becomes a structured signal.
Why incumbents won't build this
To capture decision traces, you have to be present when the decision is being made—not after. This is the key architectural question: are you in the write path or the read path?
By the time a decision lands as final state in a system of record, the why is gone. The strategic surface is the point where decisions become binding: the approval step, the redline, the escalation, the agent proposal, the human override. That is where reasoning still exists in usable form.
Operational incumbents and SORS are siloed and prioritize current state. Salesforce, ServiceNow, and Workday are all building agents on top of their existing platforms, but those agents inherit the architecture beneath them. Salesforce is built on current-state storage: it knows what the opportunity looks like now, not what it looked like when the decision was made. When a discount gets approved, the context that justified it is not preserved. You cannot replay the state of the world at decision time, which means you cannot audit the decision, learn from it, or use it as precedent.
What’s more, no incumbent sees the cross-system picture. A support escalation depends on customer tier from the CRM, SLA terms from billing, recent outages from PagerDuty, and the Slack thread flagging churn risk. No single incumbent sits in that path.
Warehouse players are entirely in the read path, not write path. Snowflake and Databricks are positioning themselves as the intelligence layer, but warehouses receive data via ETL after decisions are made. They receive the output of decisions, not the reasoning that produced them. Being close to where agents get built is not the same as being in the execution path where decisions happen.
Systems-of-agents startups have the structural advantage because they sit in the write path by default. When an agent triages an escalation, responds to an incident, or decides on a discount, it pulls context from multiple systems, evaluates rules, resolves conflicts, and acts. Because it is executing the workflow, it captures rationale at the moment decisions become binding—not after the fact via ETL, but in the moment, as a first-class record.
And because enterprise decision traces are too sensitive for ordinary access controls, whoever builds this layer must support permissioned inference, not just permissioned retrieval. A law firm cannot let one client's precedent quietly shape reasoning for a competitor; a healthcare organization cannot allow operational history to leak through abstraction. The companies that solve this earn trust that compounds just as surely as the data itself.
The platform opportunity
This will be both a platform and an application opportunity. Every incumbent is already eyeing the prize, which tells you how large it is.
For some companies, the play is owning their own context graph—building the proprietary decision infrastructure that makes their agents smarter than anyone else's in their domain. For these, a new infrastructure layer will emerge: the picks and shovels for constructing, securing, and querying context graphs at enterprise scale.
For application companies, the opportunity is building the context graphs themselves—domain-specific, cross functional, compounding systems of record for decisions. We see these emerging along three axes: operational context graphs (how the company tactically runs), customer-facing context graphs (how the company sells, supports, and retains—sales, underwriting, account management), and strategic context graphs (how the executive makes strategic decisions). Each is a distinct surface with distinct confidentiality requirements, distinct decision patterns, and distinct outcome signals.
And once these graphs become dense enough, the game changes from retrieval to prediction. Instead of "how did we handle this last time?" you can ask "if we structured the deal this way, what's likely to happen?"—grounded not in generic training data but in your organization's actual decision history and outcomes. That capability does not fully exist yet, but the companies assembling these foundations are building toward it.
The trillion-dollar rewrite
Every enterprise vertical—legal, insurance, healthcare, financial services, procurement, security—has decades of accumulated institutional judgment that has never been structured, never been compounded, never been made operational. That judgment is what makes a $2,000/hour partner worth $2,000/hour. Frontier models are raising the floor, but they’re not raising the ceiling.
The ceiling is institutional. It is the accumulated, domain-specific, outcome-tested reasoning about how this organization makes decisions under these constraints. That is what compounds and what cannot be replicated by a better base model. It’s also what’s finally becoming capturable, structurable, and learnable.
Consumer giants built trillion-dollar empires by compounding behavioral traces. The enterprise equivalent is just now becoming possible, and the prize is arguably larger. The companies that build the infrastructure to make this real will define the next era of enterprise value.
If you're building in this space, we'd love to talk.